cuda basics
in C++, CUDA
참고
[1] https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
cuda c++
- cuda c++은 nvidia gpu를 사용할 수 있도록 하는 프로그래밍 패키지이다.
- cuda c++은 c++ 언어를 extention해서 사용하고 있다.
- nvcc 컴파일러를 이용해서 코드를 컴파일한다.
- kernel 라고 불리는 c++ 함수를 이용해서 cuda c++ 코드를 작성할 수 있다.
kernel
- c++ 언어에서 cuda c++를 사용할 수 있는 c++ 함수이다.
- kernel 함수를 실행하면 gpu 상에서 코드가 실행된다.
- 함수 선언 앞에 __global__ 구분자를 넣어 정의한다.
- kernel를 실행하면 N개의 독립적인 CUDA thread가 해당 함수를 실행한다.
- cuda c++에는 기본적인 built in variable이 있고, 해당 변수를 통해서 현재 kernel을 실행하고 있는 스레드가 어떤 스레드인지 확인할 수 있다.
- 해당 kernel을 실행하고 있는 thread는 threadIdx 변수를 통해 확인한다.
Thread Hierarchy
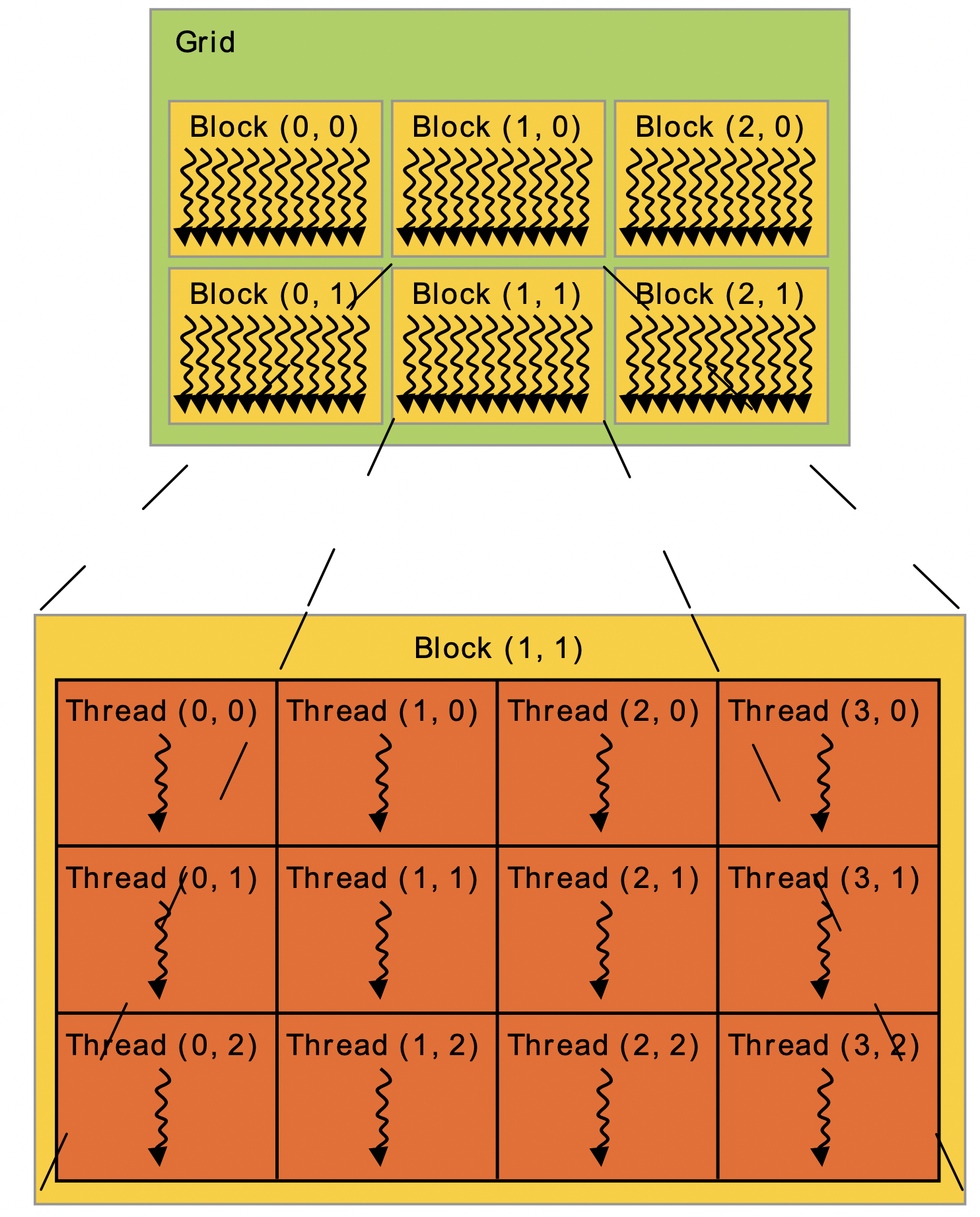
- gpu 상에서의 core 구조는 thread의 덩어리로만 이루어져있지 않다.
- grid라는 큰 틀안에 3차원의 여러 block들이 있고 block 안에 3차원의 thread들이 존재하고 있다.
- 하나의 block에는 최대 1024개의 스레드가 존재할 수 있다.
- blockDim.x 는 block당 thread 수를 의미한다.
// 1024, 1024 차원의 행렬 더하기 함수 N = 1024 __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; } int main() { dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsperBlock.x, N / threadsPerBlock.y); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); // blockIdx : 0 ~ 63 // threadIdx : 0 ~ 15 // blockDim : 16 // blackDim은 block에 존재하는 thread 수를 나타내나 보다. }
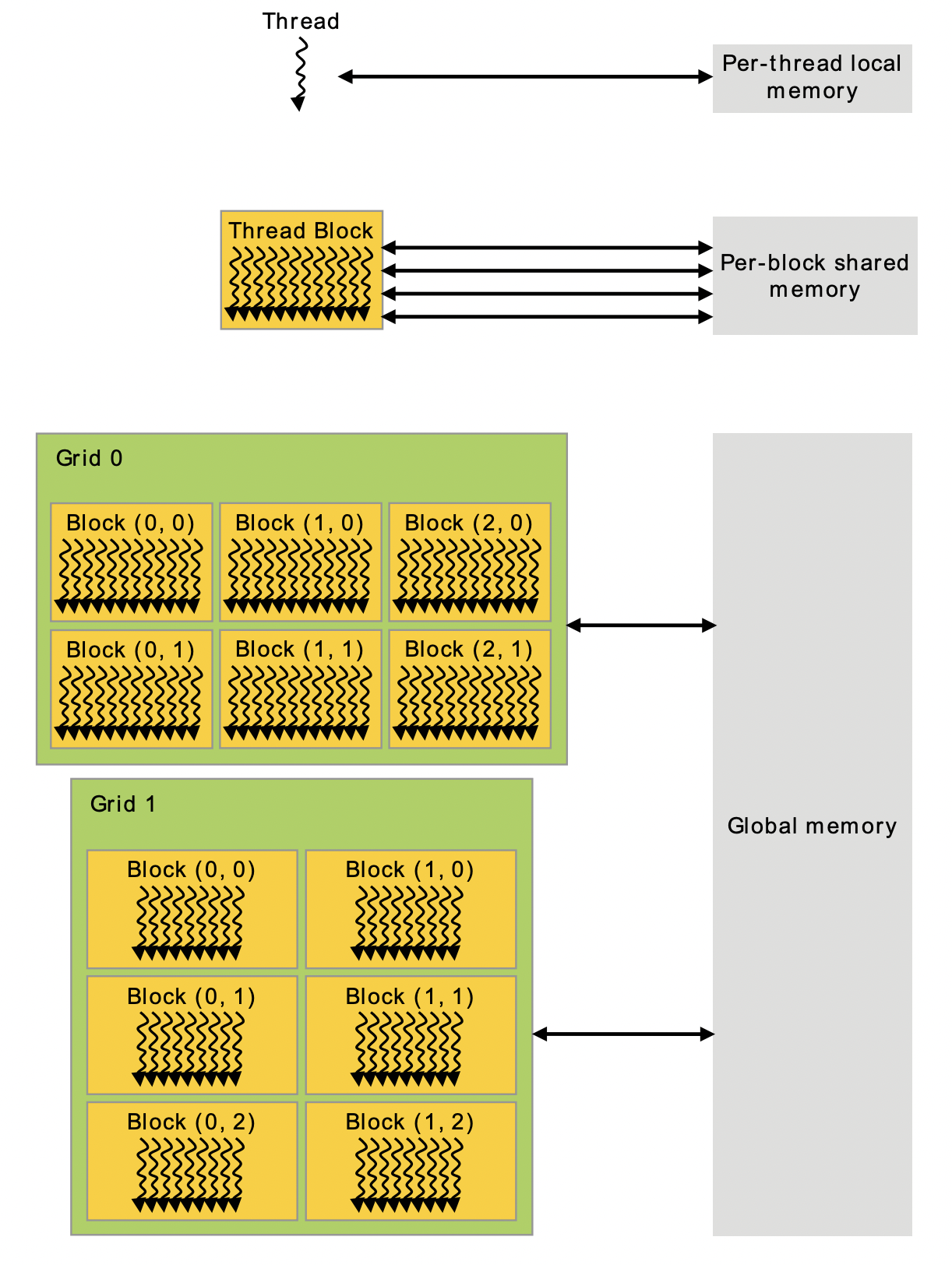
Memory Hierarchy
- 각각의 스레드에는 스레드별로 독립적으로 사용할 수 있는 private local memory가 있다.
- 하나의 블럭안의 모든 스레드에서 접근할 수 있는 shared memory가 있다.
- 모든 스레드들이 접근할 수 있는 global memory가 있다.
- 또한 constant와 texture read only memory 공간이 존재한다.
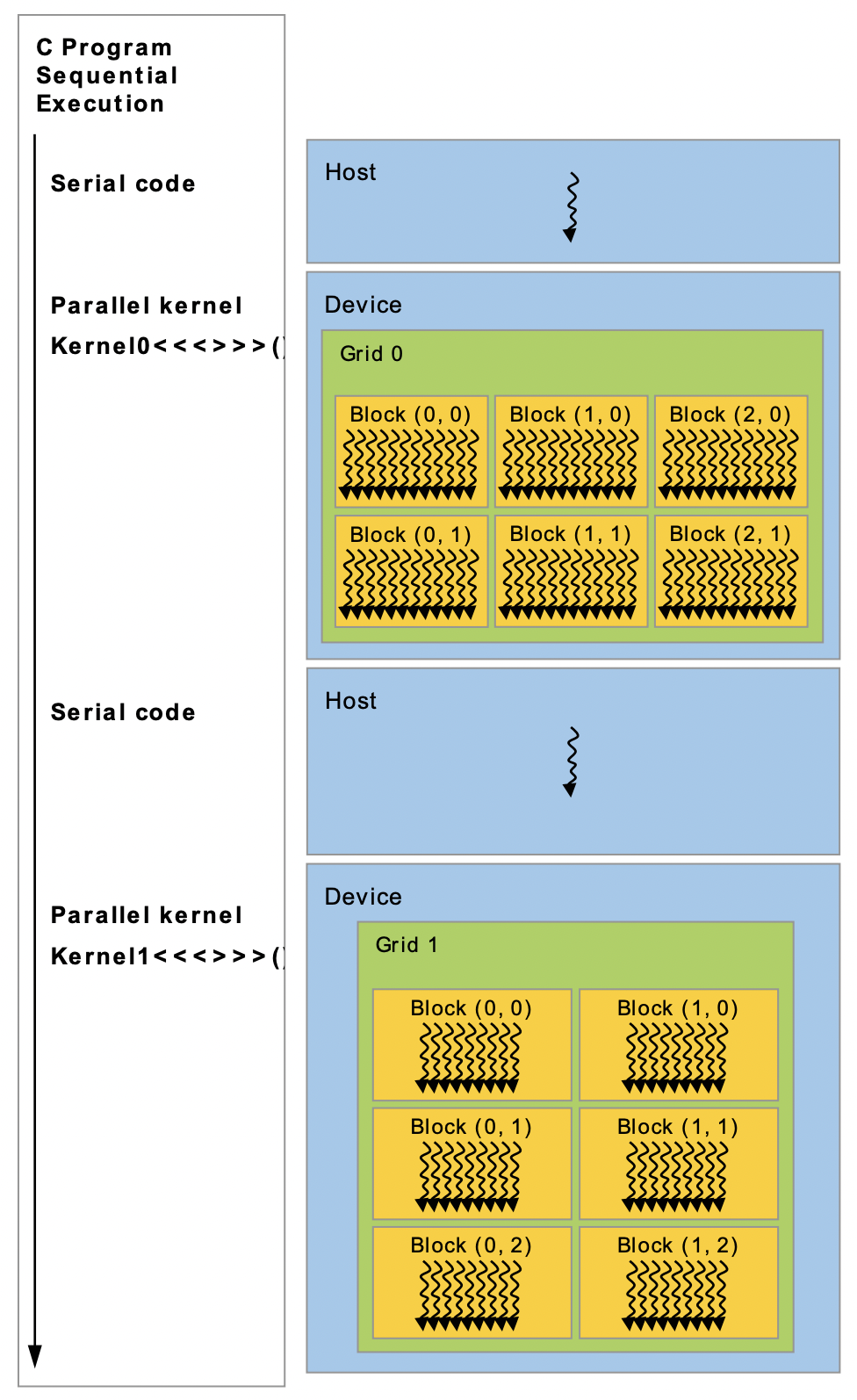
- kernel 함수가 GPU 상에서 실행된다면 나머지 C++ 코드는 CPU 상에서 실행된다.
- cuda는 host(cpu, host memory)와 별개의 메모리(device memory)를 사용한다. 이것은 하나의 프로그램상에서 host memory와 device memory간에 데이터 전송이 필요하다는 의미이다.
- Unified memory는 host와 device memory간을 연결해주는 memory 체계이다.
- Unified memory는 CPU와 GPU에서 동일한 메모리 주소를 통해 접근할 수 있다.
- Unified memory를 통해 host와 device간에 expilcitly mirror data를 필요로하지 않기 대문에 매우 효율적이라 볼 수 있다.