matrix mulplication using shared memory
in C++, CUDA
참고
[1] https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#shared-memory
Shared memory
- 동일한 cuda block안에 있는 thread들이 공용으로 사용할 수 있는 메모리.
- global memory 보다 훨신 빠른 읽기와 쓰기 속도를 가지기에 scratchpad memory 혹은 software managed cache라고 부르기도 한다.
- global memory의 접근을 최소화하고 shared memory를 사용하는 것이 최적화의 좋은 방향이다.
- 행렬의 곱셈을 1. global memory만을 사용해서, 2. shared memory도 같이 사용해서 문제를 풀어보자.
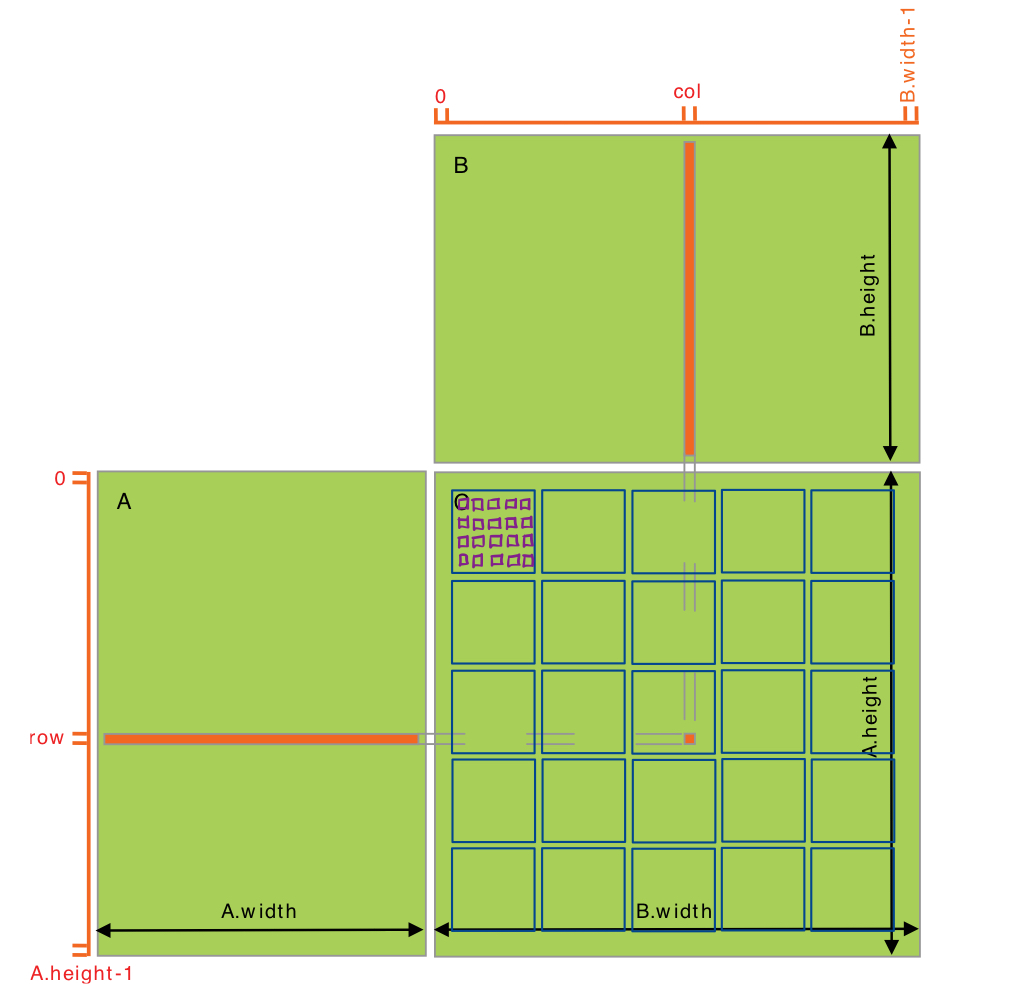
matrix multiplication using only global memory
- matrix C = matrix A \(x\) matrix B
- C의 element들을 계산하는 방식은 각각 독립적이므로 element별로 스레드를 할당해서 계산하도록 하자.
- 개별 스레드는 각각 A.width + B.height 수 만큼 global memory에 접근해야만 한다.
// matirx를 일차원 벡터로 표현하기 위해 구조체를 만듬, 왜 이렇게 하는 것인지는 모르겟지만 cuda에서 보낼때는 다들 일차원 벡터로 하더라 // M(row, col) = *(M.elements + row * M.width + col) typedef struct { int width; int height; float* elements; } Matrix; // Thread block size #define BLOCK_SIZE 16 // Forward declaration of the matrix multiplication kernel __global__ void MatMulKernel(const Matrix, const Matrix, Matrix); // Matrix multiplication - Host code // Matrix dimensions are assumed to be multiples of BLOCK_SIZE,,, 사실은 일반화 해야만 한다. void MatMul(const Matrix A, const Matrix B, Matrix C) { // Load A and B to device memory Matrix d_A; d_A.width = A.width; d_A.height = A.height; size_t size = A.width * A.height * sizeof(float); cudaMalloc(&d_A.elements, size); cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice); Matrix d_B; d_B.width = B.width; d_B.height = B.height; size = B.width * B.height * sizeof(float); cudaMalloc(&d_B.elements, size); cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix d_C; d_C.width = C.width; d_C.height = C.height; size = C.width * C.height * sizeof(float); cudaMalloc(&d_C.elements, size); // Invoke kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); // BLOCK_SIZE의 배수가 아니라면 B.width / dimBlock.x + (dimBlock.x + 1) / dimBlock.x 여야만 한다. dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y); MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); // Read C from device memory cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements); cudaFree(d_C.elements); } // Matrix multiplication kernel called by MatMul() __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Each thread computes one element of C // by accumulating results into Cvalue float Cvalue = 0; int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; for (int e = 0; e < A.width; ++e) Cvalue += A.elements[row * A.width + e] * B.elements[e * B.width + col]; C.elements[row * C.width + col] = Cvalue; }
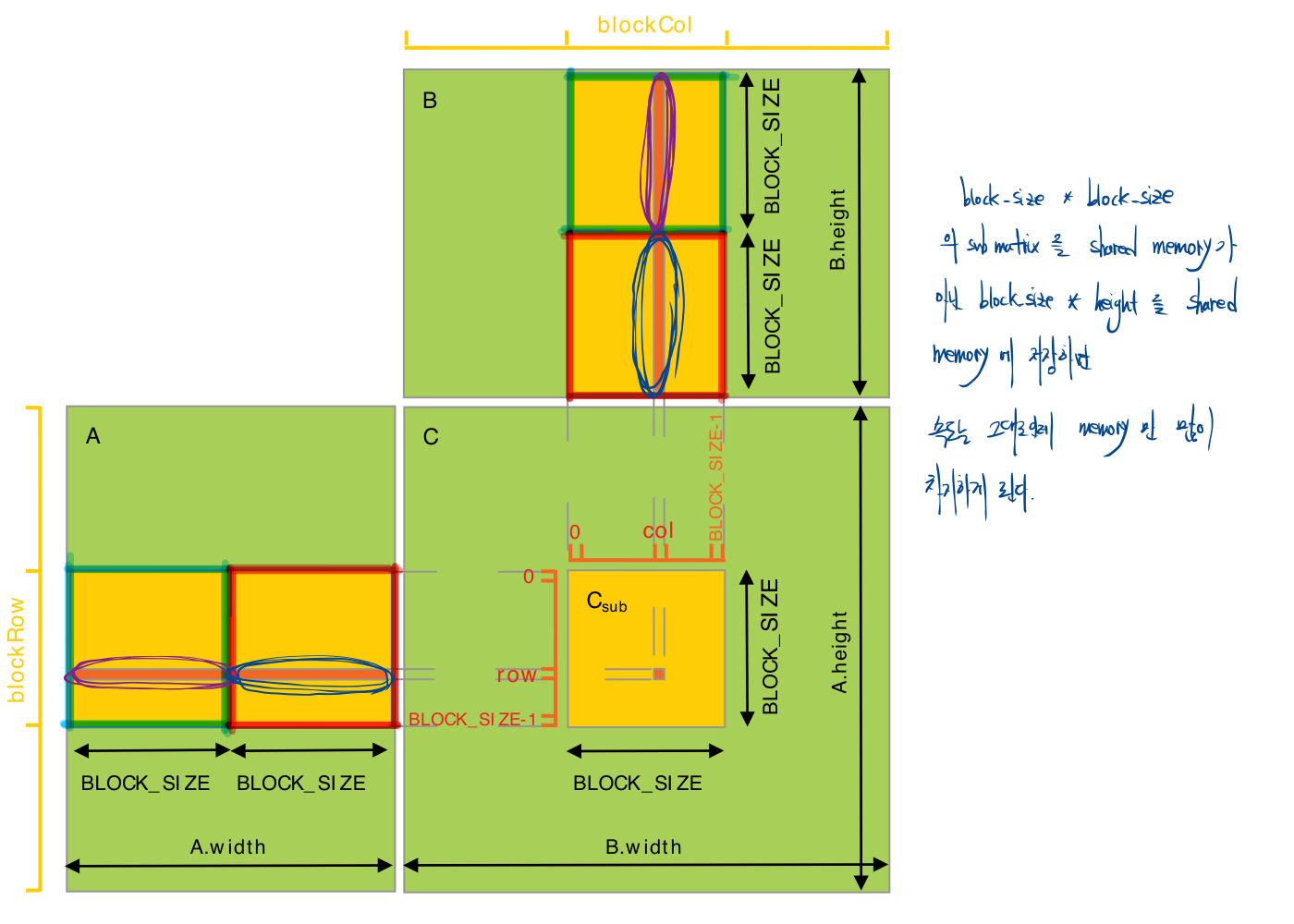
matrix multiplication with shared memory
- global memory만을 사용하여 문제를 푼 알고리즘을 보면 하나의 블럭 안에 있는 스레드들이 global memory의 동일한 데이터에 접근을 하는데, 이것을 shared memory에 저장을 하면 한번만 접근을 하는 것으로 줄일 수 있다.
- global memory의 접근을 1 / block_size * block_size 으로 줄일 수 있다.
- 메모리가 공유되기 때문에 쓸 때, shync를 맞춰야 하는 것에 유의히자.
// 앞의 global memory 문제를 풀 때와는 달리 stride가 있다. stride는 원본 matrix의 width를 나타내며, 다음 row를 가리키기 위함이다. // M(row, col) = *(M.elements + row * M.stride + col) typedef struct { int width; int height; int stride; float* elements; } Matrix; // Get a matrix element // A가 device memory에 있다고 가정한다. __device__ float GetElement(const Matrix A, int row, int col) { return A.elements[row * A.stride + col]; } // Set a matrix element // A가 device memory에 있다고 가정한다. __device__ void SetElement(Matrix A, int row, int col, float value) { A.elements[row * A.stride + col] = value; } // Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is // located col sub-matrices to the right and row sub-matrices down // from the upper-left corner of A // matrix의 row, col 번째 element가 아닌 block을 의미한다. __device__ Matrix GetSubMatrix(Matrix A, int row, int col) { Matrix Asub; Asub.width = BLOCK_SIZE; Asub.height = BLOCK_SIZE; Asub.stride = A.stride; Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col]; return Asub; } // Thread block size #define BLOCK_SIZE 16 // Forward declaration of the matrix multiplication kernel __global__ void MatMulKernel(const Matrix, const Matrix, Matrix); // Matrix multiplication - Host code // Matrix dimensions are assumed to be multiples of BLOCK_SIZE void MatMul(const Matrix A, const Matrix B, Matrix C) { // Load A and B to device memory Matrix d_A; d_A.width = d_A.stride = A.width; d_A.height = A.height; size_t size = A.width * A.height * sizeof(float); cudaMalloc(&d_A.elements, size); cudaMemcpy(d_A.elements, A.elements, size, cudaMemcpyHostToDevice); Matrix d_B; d_B.width = d_B.stride = B.width; d_B.height = B.height; size = B.width * B.height * sizeof(float); cudaMalloc(&d_B.elements, size); cudaMemcpy(d_B.elements, B.elements, size, cudaMemcpyHostToDevice); // Allocate C in device memory Matrix d_C; d_C.width = d_C.stride = C.width; d_C.height = C.height; size = C.width * C.height * sizeof(float); cudaMalloc(&d_C.elements, size); // Invoke kernel dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y); MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C); // Read C from device memory cudaMemcpy(C.elements, d_C.elements, size, cudaMemcpyDeviceToHost); // Free device memory cudaFree(d_A.elements); cudaFree(d_B.elements); cudaFree(d_C.elements); } // Matrix multiplication kernel called by MatMul() __global__ void MatMulKernel(Matrix A, Matrix B, Matrix C) { // Block row and column int blockRow = blockIdx.y; int blockCol = blockIdx.x; // Each thread block computes one sub-matrix Csub of C Matrix Csub = GetSubMatrix(C, blockRow, blockCol); // Each thread computes one element of Csub // by accumulating results into Cvalue float Cvalue = 0; // Thread row and column within Csub int row = threadIdx.y; int col = threadIdx.x; // Csub를 계산하기 위한 알고리즘 // block별로 계산해서 Cvalue에 더해준다. for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) { // Get sub-matrix Asub of A Matrix Asub = GetSubMatrix(A, blockRow, m); // Get sub-matrix Bsub of B Matrix Bsub = GetSubMatrix(B, m, blockCol); // Shared memory used to store Asub and Bsub respectively __shared__ float As[BLOCK_SIZE][BLOCK_SIZE]; __shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE]; // thread 개별로 저장을 해도 모두 공유된다. // block_size가 아닌 height나 width 전체로 저장해도 되지 않겟나 생각할 수 있지만 그것은 속도는 그대로인데 shared memory 크기만 많이 잡아 먹을 뿐이다. As[row][col] = GetElement(Asub, row, col); Bs[row][col] = GetElement(Bsub, row, col); // Synchronize to make sure the sub-matrices are loaded // before starting the computation __syncthreads(); // Multiply Asub and Bsub together for (int e = 0; e < BLOCK_SIZE; ++e) Cvalue += As[row][e] * Bs[e][col]; // Synchronize to make sure that the preceding // computation is done before loading two new // sub-matrices of A and B in the next iteration __syncthreads(); } // Write Csub to device memory // Each thread writes one element SetElement(Csub, row, col, Cvalue); }