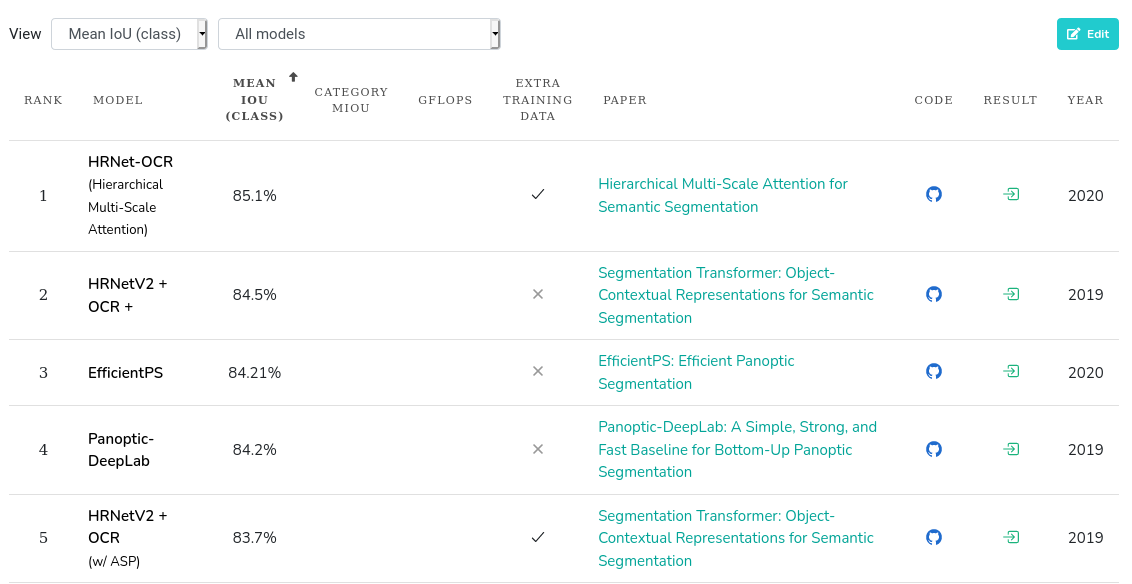
Hierachical HR-net
참고
[1] Andrew Tao, Karan Sapra, Bryan Catanzaro. Hierarchical Multi-Scale Attention for Semantic Segmentation, 2020
[2] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu, and Alan L. Yuille. Attention to scale: Scale-aware semantic, image segmentation, 2015
Segmentation분야에 대해서는 큰 관심이 없었기 때문에 읽은 논문도 없었다. 이 논문이 첫번째로 읽은 Segmentation관련 논문이라고 볼 수 있고, 이 논문은 현재(2021. 05) Segmentation 평가에서 Sota로 인정받는 논문이다.
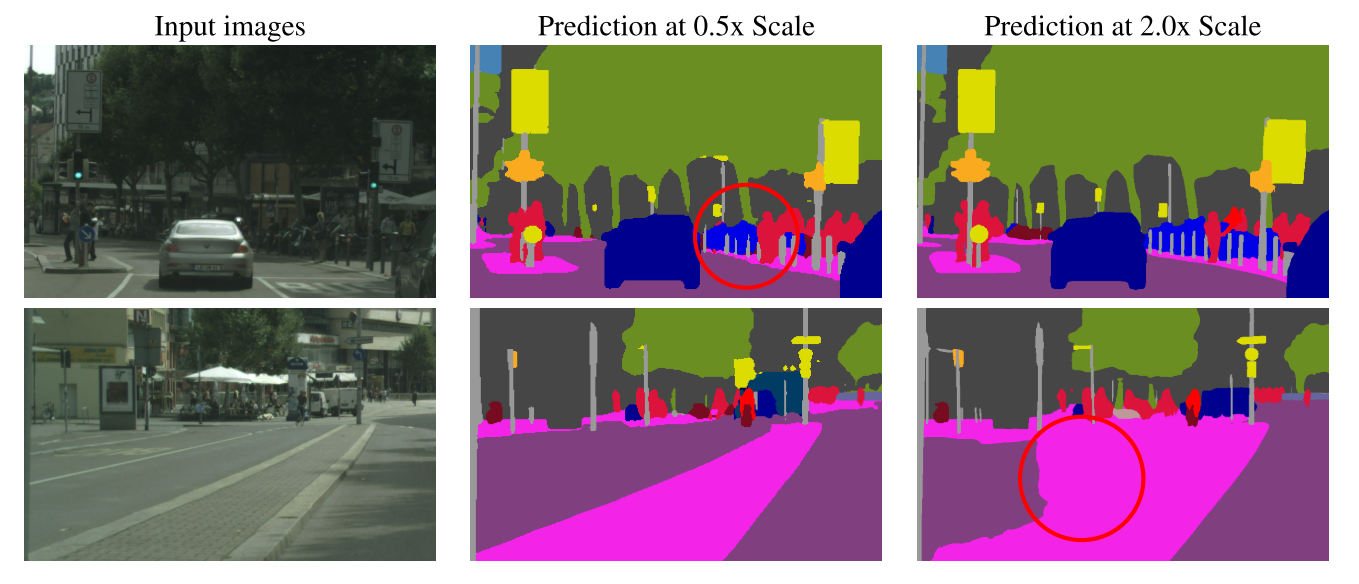
Segmentation 문제에 있어서 입력 이미지의 해상도는 결과물에 많은 영향을 끼친다. 예를 들면 같은 이미지를 다른 해상도로 같은 모델에 입력하면 저해상도 이미지에서는 비교적으로 큰 영역을 잘 잡고, 고해상도 이미지에서는 비교적으로 작은 세밀한 영역들을 잘 잡는다. 어떻게 보면 당연한 결과라고 볼 수 있는 것이 같은 모델을 사용하기 때문에 동일한 뉴런이 가지고 있는 Receptive field가 상대적으로 저해상도가 고해상도 이미지보다 넓은 영역을 가지기 때문에 더 큰 영역을 잘 잡는 것이다.
그렇기 때문에 이 전부터 MULTI-SCALE하게 Segmentation 문제를 많이 풀었다고 한다. 보통의 경우에는 여러 스케일에서의 결과물을 max pooling이나 average pooling으로 결합하는데, 이렇게 할 경우 결과물이 오히려 이전보다 더 안좋아지는 경우도 있다. 그래서 [2]에서는 Attention을 통해서 결과물을 결합하였고, max pooling과 average pooling의 메커니즘을 포함하는 학습 가능한 모델(Attention)을 통해 좋은 결과물을 보여주었다. 사실 ‘Attention all you need’ 이전의 논문에서 Attention을 어떻게 구현하는지 몰랐기 때문에 많이 궁금했었는데, 단순한 CNN 모델의 결과물을 Attention 값(weight)이라고 지칭하였다. 밑에 사진의 왼쪽 모델을 보면 각 스케일에대한 결과물을 Attention모델(단순 CNN)에 넣고 3개의 채널(3개의 스케일라서)을 출력한다.
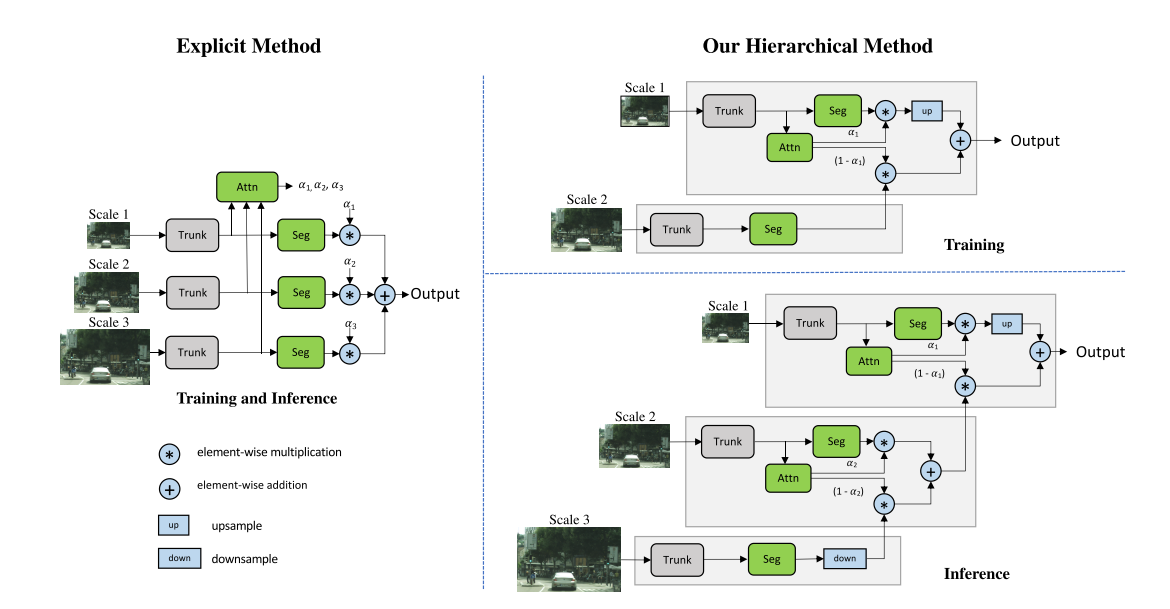
그러나 이전의 모델에서는 하나의 스케일 조합, 예를 들면 0.5배, 1배, 2배의 스케일의 조합을 통해서 학습을 하면 해당 모델은 하나의 스케일 조합에 대해서만 Inference가 가능하였다. 그리고 여러개의 스케일을 조합할 수록 계산량은 그에 비례하여 증가하였다. 이러한 문제를 해결하기 위해 이 논문에서는 Hierarchical한 방법을 채택하였고, 학습과정에서는 인접한 두개의 스케일 조합에 대해서만 학습을 진행하고 inference 할때는 인접한 두개의 스케일의 조합을 여러번 이용하여 이에 비례한 여러 스케일의 조합을 할 수 있도록 하였다. 학습시에 0.5배 스케일과 1배 스케일을 통해 이 두 스케일의 관계성을 학습한다면 이 두 스케일의 관계성은 1배 스케일과 2배 스케일에 대해서도 동일하게 적용될 수 있다는 아이디어이다. 즉, 0.5배 스케일과 1배 스케일의 학습을 통해 0.25배, 0.5배, 1배, 2배의 스케일 조합을 inference 할 수 있다.
실험 결과물을 0.5배, 1배, 2배 스케일에서 inference 퍼포먼스가 이전의 결과물과 비교해보면 computer 비용은 이론상 배 이상으로 줄어들지만 결과물의 퀄리티는 큰 차이가 없는 것을 보여주었다.
