GPT-v1
in Paper
Introduction
- NLP 문제를 다루는데 있어서, raw text를 통해 모델을 학습하는 것은 supervised learning에 대한 의존성을 완화할 수 있어 매우 중요한 해결책이다.
- 심지어 raw text를 통해 잘 학습한, 즉 풍부히 language representation을 할 수 있는 모델이 있다면 대량의 labeled dataset이 존재하는 supervised learning에서도 도움이 될 것이다.
- 이 논문에서는 unsupervised pretraining과 supervised fine tuning의 조합으로 다양한 task의 문제들을 범용적으로 풀려고 하였다.
- 이 논문의 핵심은 unlabeled dataset을 통해 good language representation을 가진 pretrained model을 만드는 것이다.
- 이 논문에서는 unlabeled dataset을 통해 language model을 만든다.
- language model이 구현도 간단하고 language representation이 범용적으로 가장 낫다고 보는 것 같다.
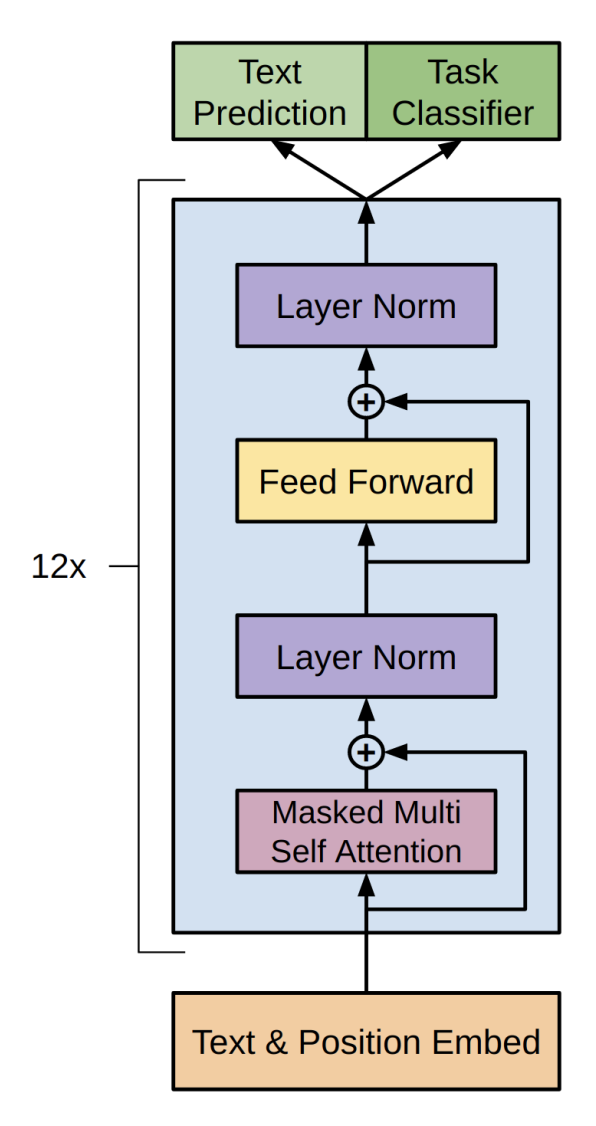
- model로는 Transformer의 decoder를 채택하였다.
Framework
- GPT의 프로세스는 Unsupervised pretraining stage와 upservised fine tuning으로 구성되어있다.
Unsupervised pretraining
\[\begin{align} %!!15 U &= \{u_1,...,u_n\} \\[1em] L_1(U) &= \displaystyle\sum_{i}^{} \log{P(u_i|u_{i-k}, ..., u_{i-1};\theta)} \end{align}\]
- unlabeled dataset을 통해서 language model을 만든다.
- dataset은 corpus of tokens의 집합이다.
- standard language model을 likelihood function으로 사용하여 MLE 학습을 한다.
- \(U\) 는 corpus of tokens이고 \(k\)는 context window의 크기이다.
\[\begin{align} %!!15 h_0 &= UW_e + W_p \\[1em] h_l &= decoderLayer(h_{l-1}) \quad \forall i \in [1, n] \\[1em] P(u) &= softmax(h_n W^T_e) \end{align}\]
- 학습 모델로는 transformer의 decoder 부분만을 사용하였다.
- language model이므로 auto-regressive하게 학습이 되므로, mask를 씌워 뒤에 등장하는 토큰을 참조할 수 없도록 학습시킨다.
- 원본 transformer의 decoder와는 다르게 multi-head attention은 제외한 multi-head self-attention과 feed-forward network 두개만을 sub-layer로 사용한다.
- n은 layer의 개수이며, \(W_e, W_p\) 는 각각 token과 position의 embedding matrix이다.
Supervised fine-tuning
\[\begin{align} %!!15 P(y|x^1,...,x^m) &= softmax(h_l^m W_y) \\[1em] L_2(C) &= \displaystyle\sum_{(x,y)}^{} \log{P(y|x^1,...,x^m)} \end{align}\]
- pretrained language model이 주어지면 해당 모델의 마지막 layer에 linear layer를 추가하여 task specific하게 모델을 구성하고 학습한다.
- specific task는 labeled dataset이 주어져야 하며, input tokens = \(\{x^1, ..., x^m\}\) 이고 그에 해당하는 label을 \(y\) 라고 지칭하겠다.
- \(h_l^m\) 은 \(h_l\) matrix의 m번째 벡터이다. C는 전체 데이터셋을 의미한다.
\[\begin{align} %!!15 L_3(C) &= L_2(C) + \lambda * L_1(C) \end{align}\]
- 실제로 학습할 시에는 language model의 objective function \(L_1(C)\) 을 auxiliary objective 으로 추가하여 학습한다.
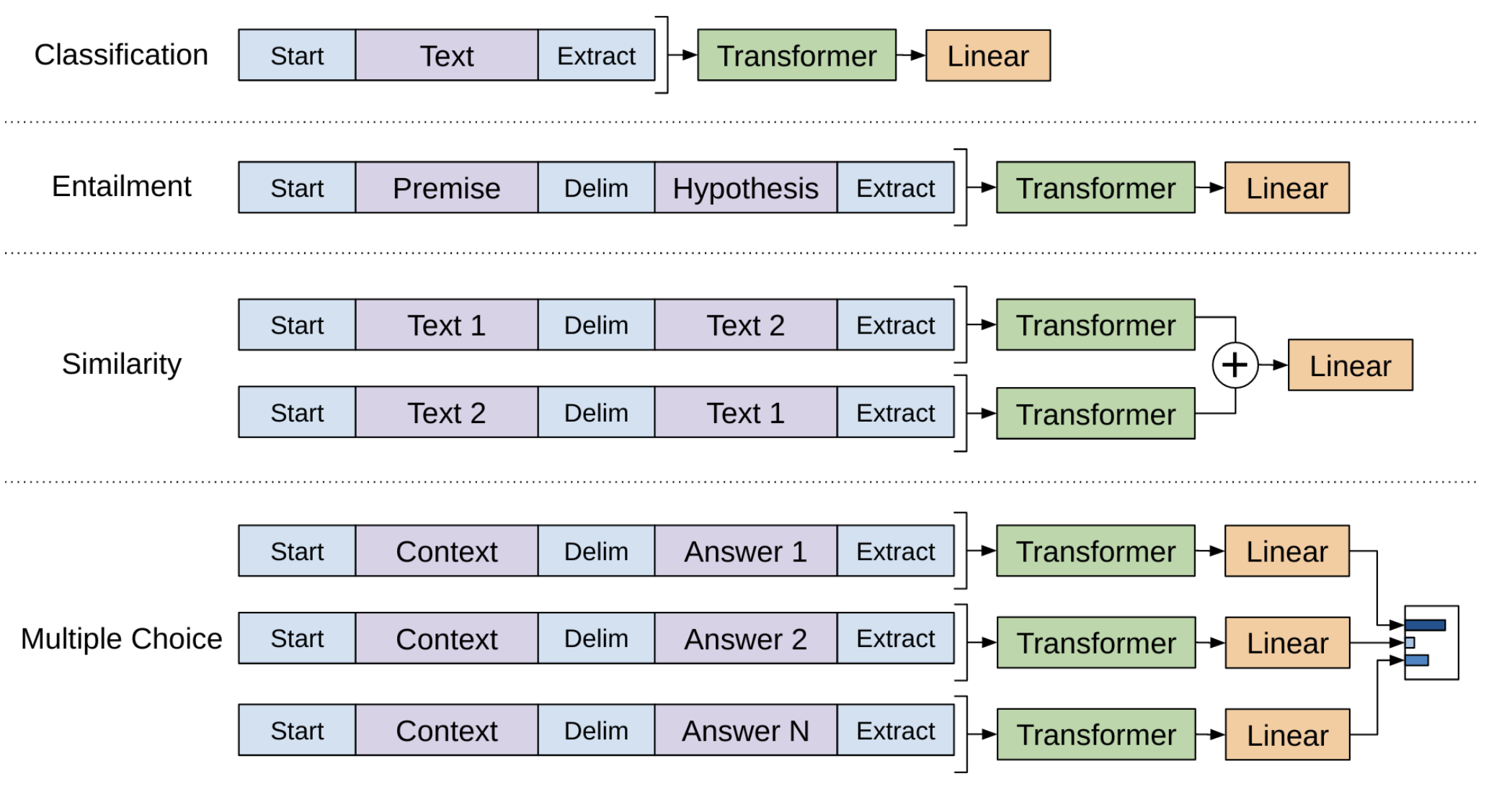
Task-specific input transformations
- gpt-v1 모델은 transformer decoder의 구조를 거의 그대로 채택했으며, task-specific fine tuning을 할 시에도 구조의 변화는 거의 없다.
- 때문에 다양한 task에 학습을 진행할 시에도 기존 transformer의 decoder에 입력되는 데이터의 형식은 그대로 보존해야 성능을 올릴 수가 있다.