Attention Is All You Need
in Paper
참고
[1] https://arxiv.org/abs/1706.03762
[2] https://nlp.seas.harvard.edu/2018/04/03/attention.html
- Introduction
- Model Architecture, Transformer
- Attention
- Position-wise Feed-Forward Networks
- Positional Encoding
- implementation
Introduction
- 기존에는 Language 같이 Sequential한 데이터를 다루기 위해 Recurrece나 Convolution operation을 sequential하게 사용한 딥러닝 모델들이 사용되었다.
- Sequential한 모델 구조를 사용한다면 parallerization한 계산에 어려움이 생기고 이것은 긴 sequence의 데이터라면 치명적으로 작동한다.
- Sequential한 모델 구조를 사용하여 긴 sequence의 데이터를 다루면 앞에 있는 토큰과 상대적으로 멀리 뒤에 있는 토큰과의 연관성을 계산하기 힘들어진다.(a number of operations, gradient vanishment 등등)
- long term memory(gradient vanishment 개선)나 Recurrence 구조에 Convolution operation(parallel operation)을 사용해서 위와 같은 문제들을 개선하긴 했지만(ByteNet, ConvS2S 등등) Sequential 구조의 근본적인 문제들은 여전히 남아있었다.
- 이 논문 이전에도 recurrent하게 attention mechanism을 사용한 모델들은 좋은 결과를 보여줬었다.
- 이 논문에서는 Sequential한 RNN이나 Convolution을 전혀 사용하지 않은 오로지 Attention operation만을 사용하여 모델을 구성하였고 좋은 결과를 보여주었다.
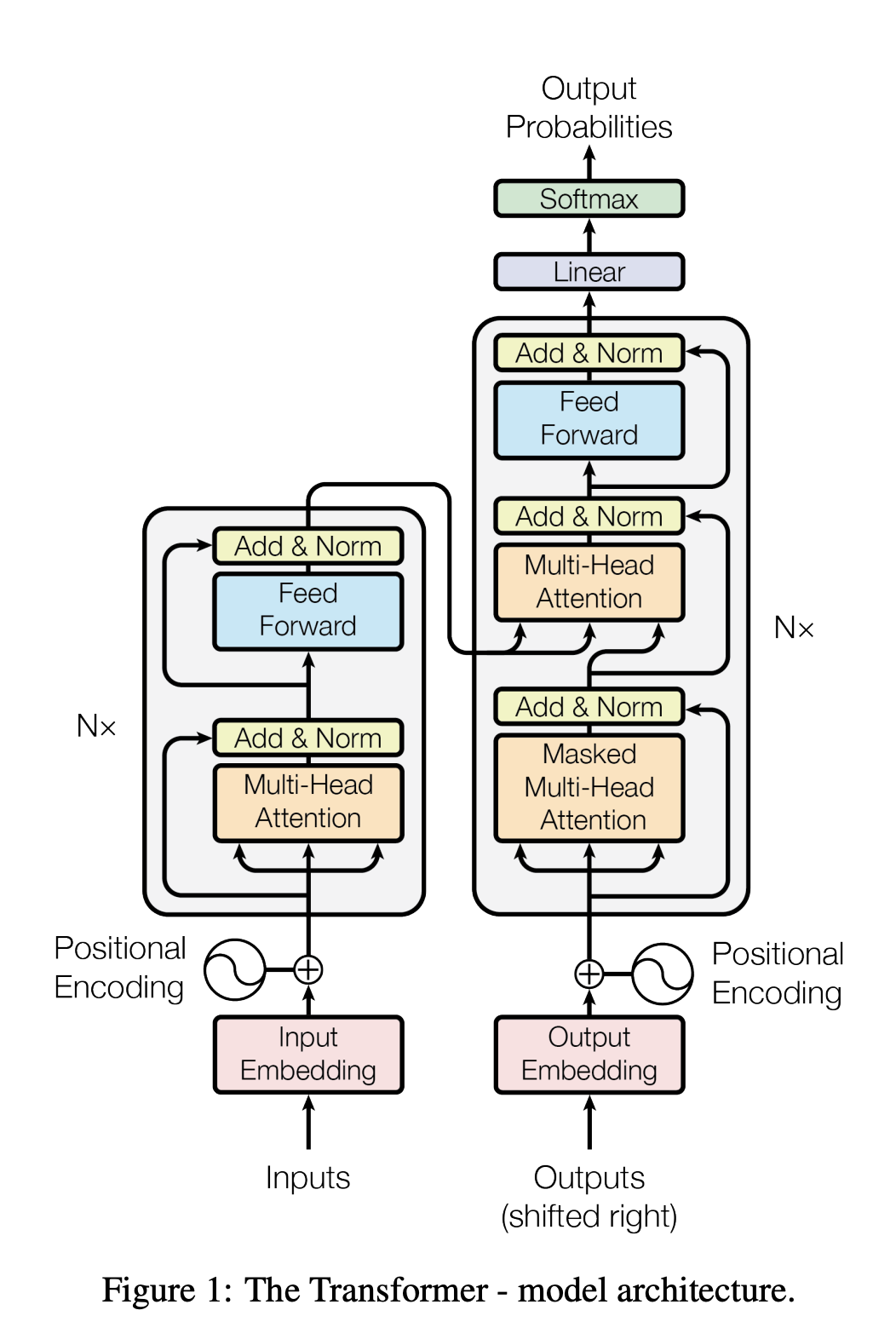
Model Architecture, Transformer
- 기존의 다른 Sequential 모델의 기본적인 구조 Encoder-Decoder 구조를 채택한다.
- Encoder는 입력 sequence of symbol representation : \((x_1, ..., x_n)\)을 continuous representation \((z_1, ..., z_n)\)으로 매핑시킨다.
- Decoder는 continuous representation \((z_1, ..., z_n)\)을 output sequence \((y_1, ..., y_n)\)으로 매핑시킨다.
Encoder
- encoder는 \(N\)개의 동일한 layer로 구성되어있다.
- 각각의 layer는 2개의 sub-layer로 구성되어있다. multi-head self-attention와 position-wise fully connected feed-forward network이다.
- 각각의 sub-layer에는 residual connection와 layer normalization을 사용하였다. 즉 \(LayerNorm(x + Sublayer(x))\).
Decoder
- decoder 또한 encoder와 마찬가지로 \(N\)개의 동일한 layer로 구성되어있다.
- 각각의 layer는 3개의 sub-layer로 구성되어있다. 2개는 encoder의 sub-layer와 동일하고 나머지 하나는 multi-head attention이다.
- multi-head self-attention은 encoder와 뒤에 나오는 토큰을 참조하는 것을 방지하기 위해 mask를 씌워 계산한다. 즉 i번째 위치의 토큰은 오로지 i이전의 토큰을 통해서만 계산된다.
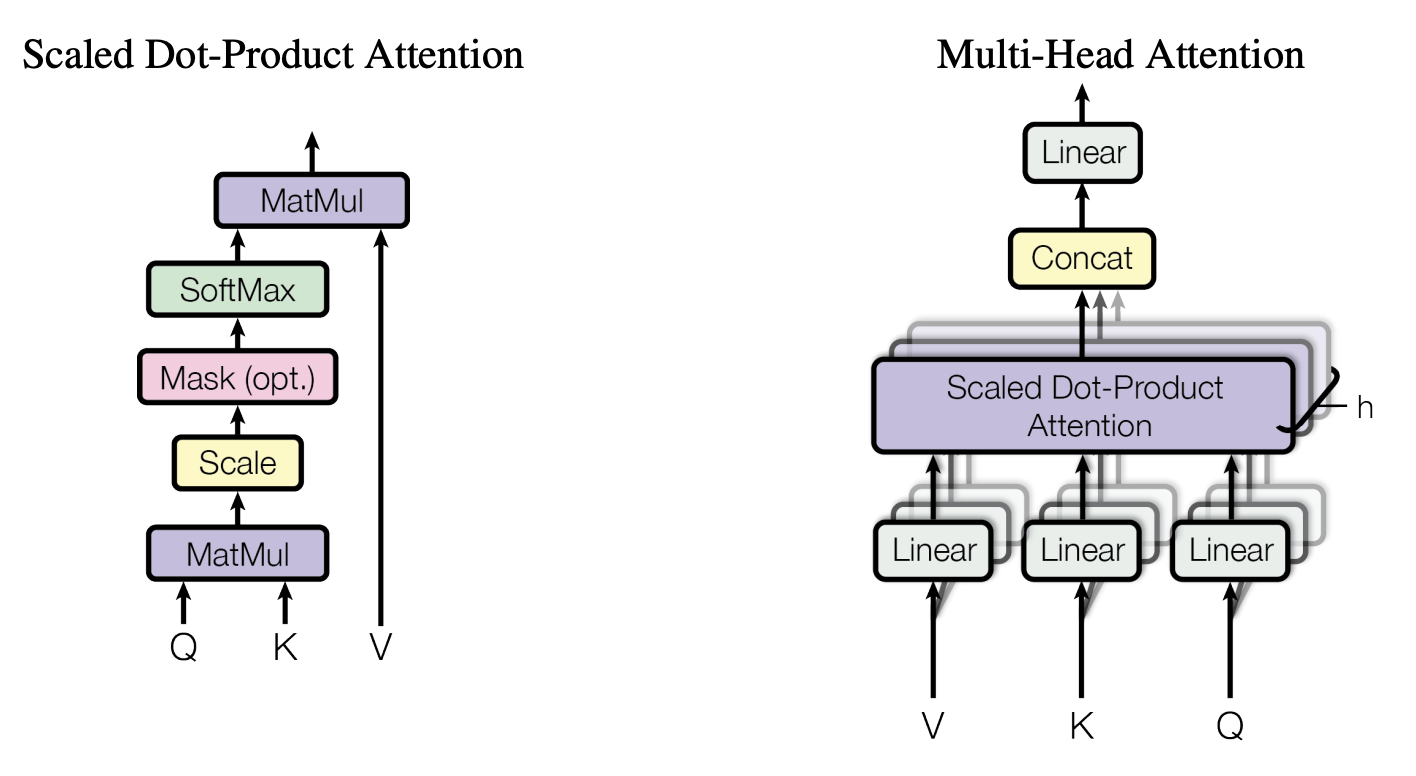
Attention
- Attention mechanism은 하나의 query와 key-value set을 하나의 output으로 매핑하는 것이다.
- query, key-value는 모두 벡터이다.
- output은 value의 weighted-sum으로 계산된다.
- value 벡터의 특정 element에 곱해지는 weight는 해당 value의 key와 query간의 similarity 값이다.
Scaled Dot-Product Attention
\[\begin{aligned} %!!15 Q: n * d_k \\[1em] K: m * d_k \\[1em] V: m * d_v \\[1em] Attention: n * d_v \\[1em] Attention(Q, K, V) &= softmax(\frac{QK^T}{\sqrt{d_k}})V \\[1em] \end{aligned}\]
- i번째 Query와 j번째 Key간에 similarity를 계산하기위해 Dot-Product를 이용한다.
- similarity의 값을 normalize 하기 위해 \(\sqrt{dimention}\) 으로 나눠준다.
- vector의 dimension이 많이 커진다면, dot product 값의 스케일이 그에 비례하여 커질 것을 예상하고 이것을 softmax 함수에 넣는다면 gradient 값이 매우 작아지는 것을 의심하기 때문에 dimension의 크기로 나눠주는 것이다.
- similarity를 matrix operation으로 계산을 할 수 있기에 효율적으로 계산할 수 있는 장점이 있다.
Multi-Head Attention
\[\begin{aligned} %!!15 MultiHead(Q, K, V) &= Concat(head_1, ..., head_h)W^O \\[1em] head_i &= Attention(QW^Q_i, KW^K_i, VW^V_i) \\[1em] \end{aligned}\]
- 각각의 query와 key에 하나의 attention mechanism을 적용하는 것이 아닌, 여러번의 attention 함수를 적용하는 것.
- 한개의 vector를 여러개의 vector로 나눠서 여러개의 similarity 값을 구하는 것으로 하나의 element 값이 매우 크면 dot product 값도 그 element에 치중되어 다른 element들은 무시되는 것을 해결할 수 있어, 좀더 다양하게 element들을 고려할 수 있어 장점이 되지 않을까 생각함.
Application of Attention
- encoder에 있는 self-attention layer는 모든 query와 key, value를 모두 같은 vectors, 이전의 layer의 output vectors로 부터 가져온다.
- encoder에서 self-attention을 계산할 시, 모든 position의 similarity를 계산할 수 있다. 그렇기에 하나의 position의 vector는 모든 position의 vector의 linear combination으로 계산된 것이다.
- decoder에 있는 self-attention layer는 encoder와 다르게 모든 position을 고려하지 않는다. 이전의 position에 있는 vector들만을 고려한다. 이렇게 해야 다양한 길이의 문장을 inference할 수 있다.
- decoder에 있는 attention layer는 query는 이전 layer의 output vectors로 key, value는 encoder의 output vectors로 부터 가져온다.
Position-wise Feed-Forward Networks
\[\begin{aligned} %!!15 x &: n * d \\[1em] W_1 &: d * (d*4) \\[1em] W_2 &: (d*4) * n \\[1em] FFN(x) &= max(0, xW_1 + b_1)W_2 + b_2 \\[1em] \end{aligned}\]
- Attention의 output에 linear transformation을 적용한다.
- position마다 동일한 linear transformation을 적용하기에 Position-wise라는 용어가 붙었다.
- kernel size가 1인 convolution을 적용하는 것과 동일하다.
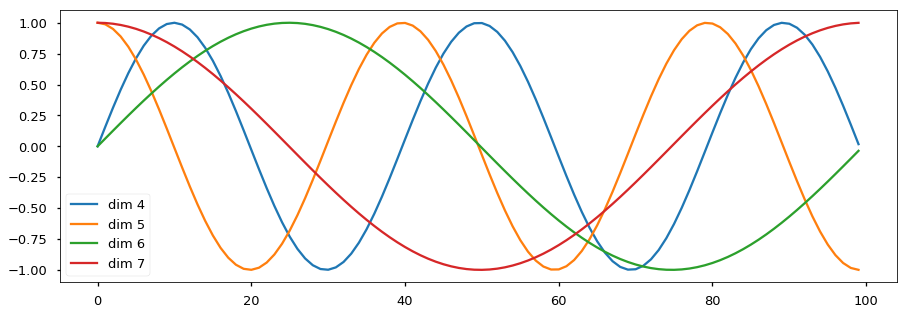
Positional Encoding
\[\begin{aligned} %!!15 d &: \text{dimension of vector} \\[1em] PE_(pos, 2i) &= sin(\frac{pos}{10000^{2i/d}}) \\[1em] PE_(pos, 2i+1) &= cos(\frac{pos}{10000^{2i/d}}) \\[1em] \end{aligned}\]
- Attention operation을 적용하면 모든 position에 따른 연관성을 계산할 수 있지만, 각각의 position이 어디에 위치하여 있는지에 대한 위치정보는 잃게된다.
- relative position 정보나 absolute position 정보를 추가해줘야만 하는데 absolute position 정보는 데이터의 길이에 따른 scale 값이 매우 달라질 수 있기에 relative position 정보를 추가해주도록 한다.
- position encoding은 Query vector와 동일한 dimension을 가지고 있도록 하고, 단순히 Query vector에 position encoding 값을 더함으로써 위치 정보를 추가해준다.
- 이 논문에서는 sin과 cos 함수를 이용해서 relative position 정보를 표현하였다.
implementation
\[\begin{aligned} %!!15 입력 &: <sos>, word_1, word_2, ..., word_n \\[1em] 출력 &: word_1, word_2, ..., word_n, <eof> \\[1em] \end{aligned}\]
- Training 시에는 decoder에 입력 쿼리로 들어가는 target sequence들이 한번에 들어간다.
- target sequence의 가장 앞에 있는 토큰은 <sos> 토큰이다.
- inference 할때에는 우선 \(<sos>\) 토큰을 입력으로 넣고 \(outWord_1\) 을 출력으로 뱉은 다음 \(<sos>, outWord_1\) 을 입력으로 넣고 \(outWord_1, outWord_2\) 을 출력으로 뱉는다. 이런식으로 \(<eof>\) 가 출력될 때까지 반복한다.
