BERT
in Paper
참고
[1] https://arxiv.org/pdf/1810.04805.pdf
Introduction
- 여러 language 관련 task를 푸는데 있어서, 범용적인 language model을 pretraining 하여 사용하는 것은 이미 좋은 성능을 나타낸다고 알려져 있다.
- gpt 같은 기존의 pretraining 모델들은 auto-regressive한 단방향의 language model을 학습하였다.
- 그러나 실제 language의 단어들은 단방향으로만 영향을 받는 것이 아닌 그 뒤에 등장하는 단어들로부터도 영향을 받는다.
- 이 논문에서는 더욱 강한 language representation model을 만들기 위해 단방향이 아닌 양방향의 bidrectional language representation을 pretraining 모델로 채택하였다.
- gpt에서의 Transformer의 decoder를 사용한 것과는 반대로 이 논문에서는 Transformer의 encoder를 사용하여 pretrained model을 만들었다.
BERT
- BERT는 pre-training 과정과 fine-tuning 과정 two step으로 프로세스를 취한다.
- pre-training 과정에서는 unlabeled dataset을 이용해서 학습을 진행한다.
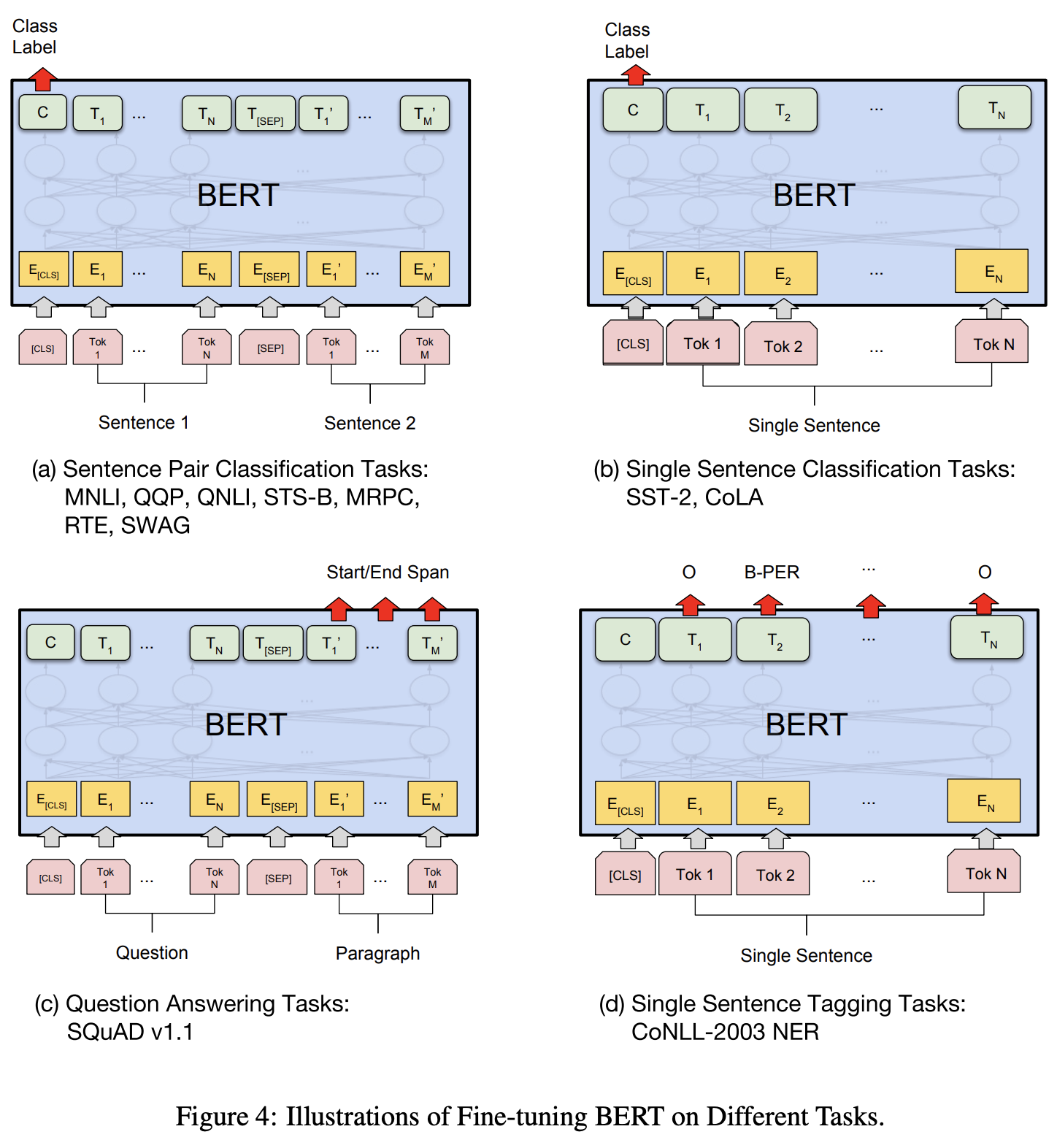
- fine-tuning 과정에서는 pretrained model을 그대로 사용하고 specific task의 labeled dataset을 이용해서 model을 학습한다. 모든 task에도 BERT의 모델 구조는 변하지 않는다.
- GPT의 auto-regressive한 self attention과는 다르게 BERT는 bidirectional self attention을 사용하였다.
- BERT 모델을 pretraining 시키는 데 있어서, 다양한 task에 적합한 pretrained model을 만들기 위해, 즉 다양한 task란 single sentence을 다루는 task와 a pair of sentences를 다루는 task 등이 있을 수 있다.
- BERT는 pretraining 시키는 데 있어서, single sentece or two sentences를 이용한다. ex) <Question, Answer>
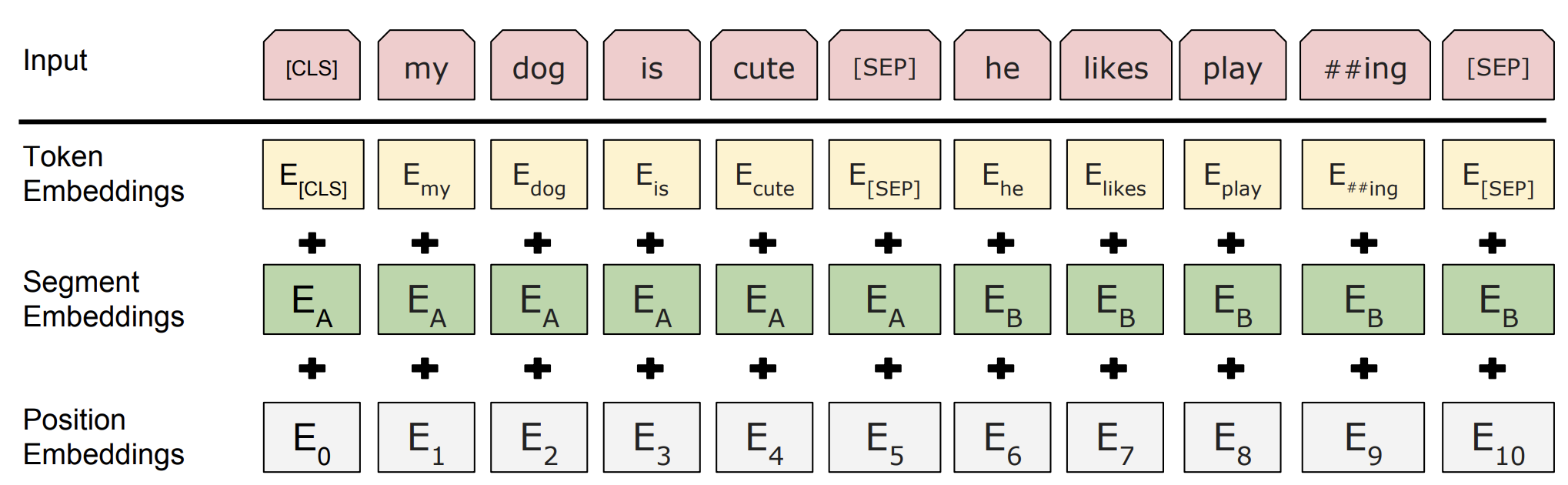
- BERT에 입력으로 들어가는 sentence의 첫번째 토큰은 항상 classification token [CLS] 토큰이다. 이 위치에 해당하는 output token은 fine-tuning시에 classfication task의 class 정보를 나타내도록 학습되기 위함이다.
- 데이터 중 sentence 쌍은 하나의 sentence로 합치게 되고, 두개의 sentence를 구분하기 위해 중간에 [SEP] 토큰을 넣고, sentence A or sentence B 에 속해있다는 것을 인지시켜주기 위해 segment embedding 기법을 추가한다.
pre-training BERT
- 기존의 left-to-right or right-to-left language model과 다르게 BERT는 bidirectional language representation model을 만들려고 했고, 거기에는 두가지 unsupervised 기법을 사용했다.
Masked LM(MLM)
- standard conditional language model는 오로지 left-to-right or right-to-left로만 학습할 수 있었다.
- BERT는 bidirectional language model을 학습시키기 위해 input token에 random하게 mask를 씌웠고, 이 과정을 masked LM 이라고 지칭하기로 했다.
- mask가 씌워진 위치에 해당하는 단어를 맞추는 식으로 학습이 진행된다.
- 이 방법의 단점으로는 pre-training 과정과 fine-tuning 과정의 불일치를 들 수 있다.
- [MASK]를 씌우는 과정은 fine-tuning 과정에서는 일어나지 않고, 이것은 두 과정간에 입력되는 데이터의 형식이 다르다는 것을 의미한다.
- 그래서 랜덤하게 선택된 모든 토큰에 [MASK] 토큰을 씌우지 않고, 일정량은 그대로 유지하고, 또 일정량은 다른 랜덤한 토큰으로 대체하는 방식으로 해결할려고 하였다.
Next Sentence Prediction (NSP)
- 두개 이상의 sentence의 관계를 학습하기 위한 방법이다. 이것은 standard language model로는 문장간의 관계를 알기는 힘들다.
- BERT는 두개의 sentence 문장의 관계를 semi-supervised classification task의 학습으로 문제를 해결한다.
- 학습 데이터의 절반은 이어진 문장의 데이터이고 나머지 절반은 이어지지 않은 관계 없는 문장의 데이터이다.
- 이어진 문장의 데이터는 output의 첫번째 위치에 있는 값이 IsNext class를 가리키도록, 관계 없는 문장의 데이터는 NotNext class를 가리키도록 학습이 된다.
Fine-tuning
- pretrained BERT는 bidirectional language representation을 할 수 있고, 두개 이상의 문장의 관계도 다룰 수 있기 때문에 다양한 task에 적합하게 fine-tuning할 수 있다.
- 일반적인 두개 이상의 문장을 다루기 위한 다른 모델들은 각각의 문장을 따로 인코딩을 하고 bidirectional cross attention을 이용해서 문장간의 관계를 알아낸다.
- 그러나 BERT는 이미 pre-train 과정에서 두 문장간의 관계를 학습하였기에 그대로 fine-tuning에 사용될 수 있다. 단순히 여러 문장을 연결해서 입력으로 넣으면 된다.
- gpt 처럼 다양한 task에 사용될 수 있도록 모델의 마지막 layer에 specific task를 풀기 위한 layer를 추가하여 output shape을 맞추고 fine-tuning을 진행한다.