ViT
in Paper
참고
[1] https://arxiv.org/pdf/1810.04805.pdf
코드
https://github.com/tinnunculus/vit/blob/master/vit.ipynb
Introduction
- 본 논문에서는 NLP 분야에서 적용된 standard Tranformer를 그대로 이미지에 적용하였다.
- 그동안에 컴퓨터 비젼 분야에서도 Transformer를 적용시킬려는 연구들이 있었지만, Attention과 Convolution을 같이 사용하거나 Convolution 없이 Attention만을 사용하였지만 Transformer 와는 다른 구조(convolution like)를 채택한 연구들이 있었다.
- standard Transformer를 이미지에 적용시키기 위해 이미지를 패치 단위로 쪼갠 뒤
- 패치를 벡터로 Flatten 하고 Tranformer에 입력 토큰으로 들어갔다.
- Convolution operator와는 다르게 Tranformer는 translation equivariance, locality 같은 inductive biases가 부족하기 때문에 이미지 학습에 어려움이 있다.
- 그렇기 때문에 많은 데이터의 학습이 필요하다.
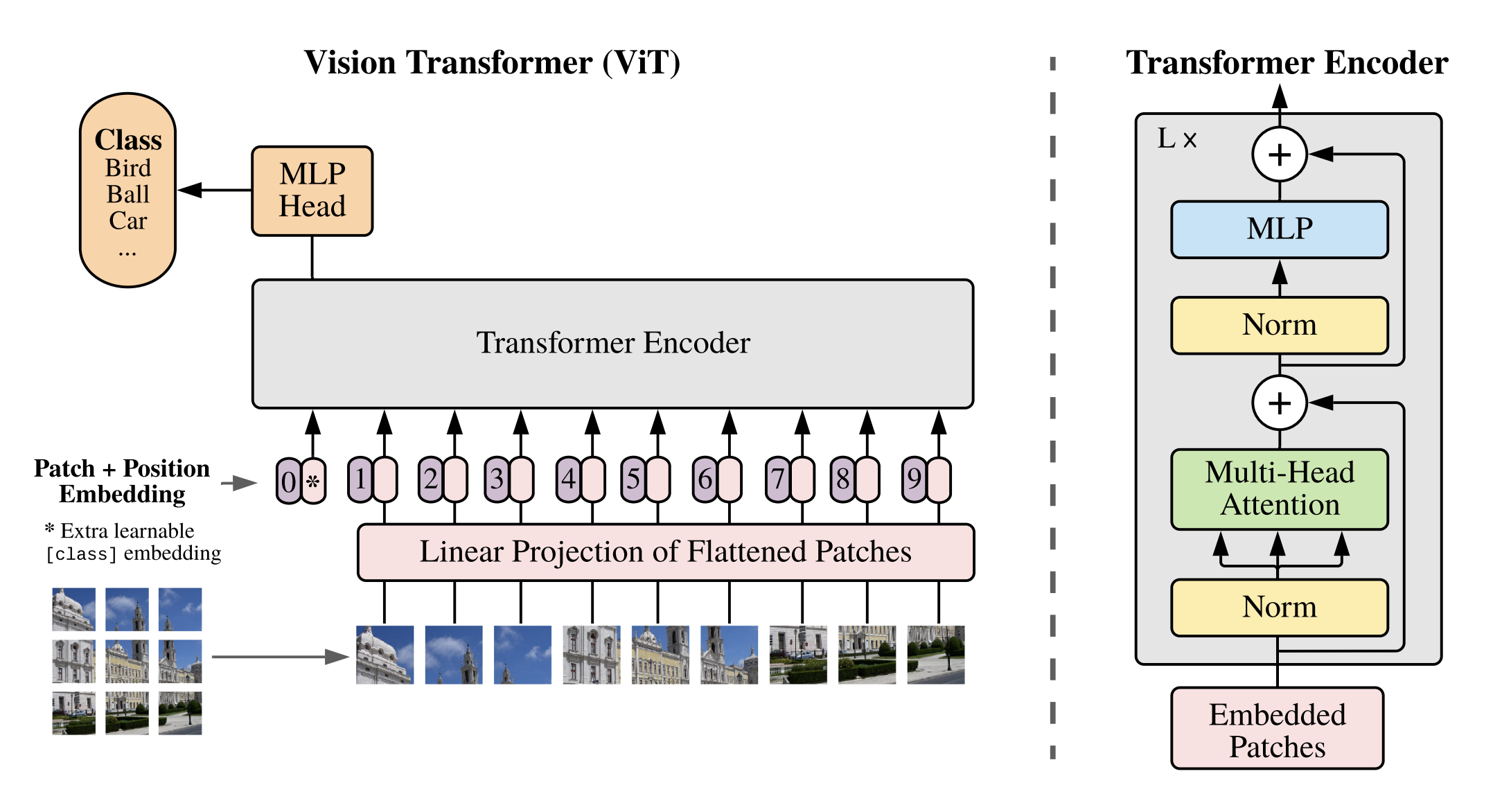
Vision Tranformer(ViT)
- standard Tranformer는 2D 데이터를 입력으로 받지 않는다.
- 때문에 우선 이미지 \(x \in \mathbb{R}^{H \times W \times C}\) 를 \(N\) 개의 패치(크기 \(P\)) 단위로 쪼개어 \(x \in \mathbb{R}^{N \times (P^2 \cdot C)}\) 의 형태로 바꿔준다.
- 따라서 패치의 개수 \(N = HW/P^2\) 이다.
- BERT와 유사하게 입력으로 들어가는 가장 앞에 있는 토큰으로 [class] 토큰을 사용한다. Tranformer에 마지막 단에 [class] 토큰이 있는 위치에 Linear mapping을 걸쳐 class 아웃풋을 출력한다.
- 또한 다른 Tranfomer와 동일할게 토큰에 Position embedding을 더한다.
- Position embedding으로 Standard Tranformer는 cos, sin 함수를 이용하였지만, 여기서는 단순히 Learnable Parameter를 더하여 위치정보를 학습한다.
- 저해상도 이미지에 pretraining 되었고 고해상도 이미지에 Fine tuning하기 위해서는 Position embedding을 그대로 사용할 수 없으므로 2D 이미지를 기준으로 interpolation을 하여 fine tuning한다.
- 본 vit 논문에서는 inductive biases를 해결하기 위한 대책은 제시하지 않고 많은 데이터를 학습함으로써 개선이 된다고 주장한다.
- 단순히 이미지를 패치단위로 쪼개는 것 말고 이미지를 한번 CNN 네트워크를 걸쳐 출력된 feature map을 토큰화 시켜 Tranformer에 넣는 방법도 있다.