DETR
in Paper
참고
[1] https://arxiv.org/pdf/2005.12872.pdf
[2] https://github.com/facebookresearch/detr
코드
https://github.com/tinnunculus/detr/blob/main/detr.ipynb
Introduction
- 기존의 딥러닝 기반의 object detector 모델들은 region proposal을 추출하고 해당 box를 기반으로 해서 정답 box를 찾는 방식이 많았다.
- 이러한 방식은 학습을 하는데 어려움이 있었는데, 수 많은 region proposal 중에 어느 것을 정답 box와 비교를 해야하는지에 대한 문제였다.
- 기존의 방식은 수 많은 결과 box 중에 정답 box 와 iou 값이 특정 기준치 이상인 것만 정답과 비교하고 나머지는 학습시키지 않는다.
- 이것은 매번 모델이 출력한 결과물을 region proposal 중에 몇개를 뽑아야하는 정제(후처리)해야만 하는 작업이 필요하다는 의미이다. 설령 학습이 완료된 후 inference 과정에서도 마찬가지이다.
- 이 논문에서는 이러한 문제를 해결하고 End-to-End로 결과물을 출력하는 모델 DETR을 만든다. DETR은 어떠한 후처리 과정도 필요하지 않는다.
- 이 논문에서는 object detection 문제를 direct set prediction 문제로 인식하고 해결한다.
- DETR의 핵심 요소는 the conjunction of the bipartite matching loss 와 Transformer(non-autogressive)의 사용이다.
- 많은 부분에서 좋은 결과를 내었지만 작은 object를 예측하는 부분에서는 낮은 퍼포먼스를 보여주었다.
set prediction loss
- DETR은 기본적으로 고정된 크기 N의 결과물을 출력한다. N은 대체적으로 object의 개수보다 크다.
- 학습을 위해 DETR에서는 N개의 결과물을 정답 object와 1대1로 매칭을 시키고, 매칭된 결과물을 정답에 맞추는 식으로 학습한다.
- 이를 위해서는 우선 1대1로 매칭을 시켜야 한다. 대개의 경우 정답 object의 수보다 N이 크기 때문에 결과물 중에 매칭되지 않은 결과물들은 모두 no object class로 설정된다.
- 매칭 알고리즘은 매칭에 따른 cost 함수를 만든 뒤 Hungarian algorithm을 이용하여 구한다. 참고로 매칭 알고리즘은 Back propagation이 될 필요가 없기 때문에 어떤 알고리즘을 사용해도 상관 없다.
- scipy에 linear sum assignment 함수를 이용하면 바로 구할 수 있다.
- 매칭이 완료되면 매칭된 box끼리 box loss를 구하고, no object class를 포함하여 모든 probability loss를 구하여 loss function을 완성한다.
- object class의 수보다 no object class의 수가 월등히 많기 때문에 파라미터를 통하여 그 값을 조정한다.
- bounding box loss 는 기본적으로 l1 loss를 사용하지만 l1 loss는 그 값이 box의 크기에 따라 값의 scale이 달라지는 특성이 있기 때문에 iou loss도 같이 포함하여 계산한다. iou는 크기의 비율이기 때문에 scale 에 영향을 받지 않는다.
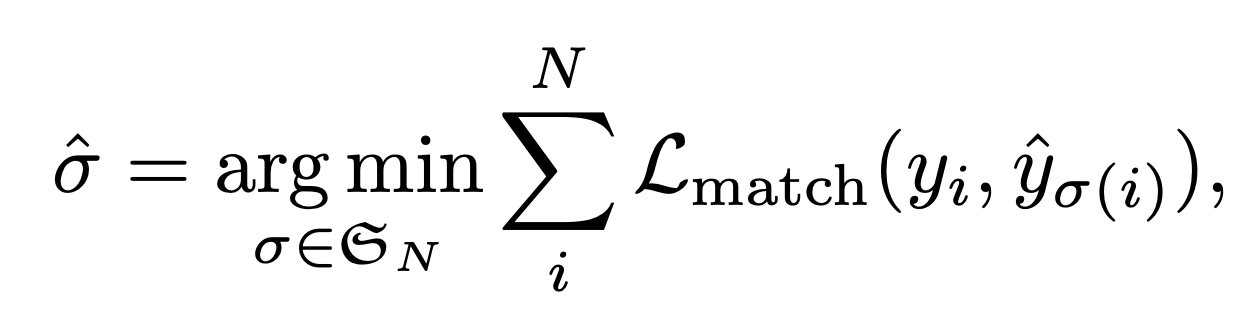
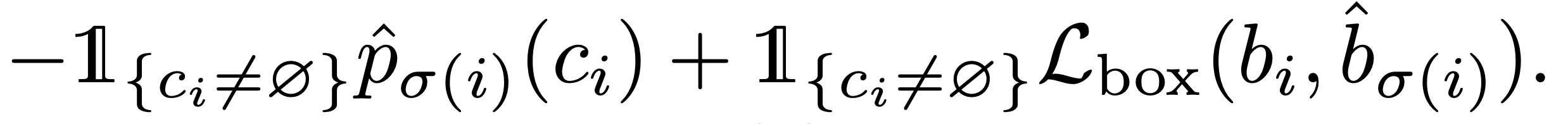
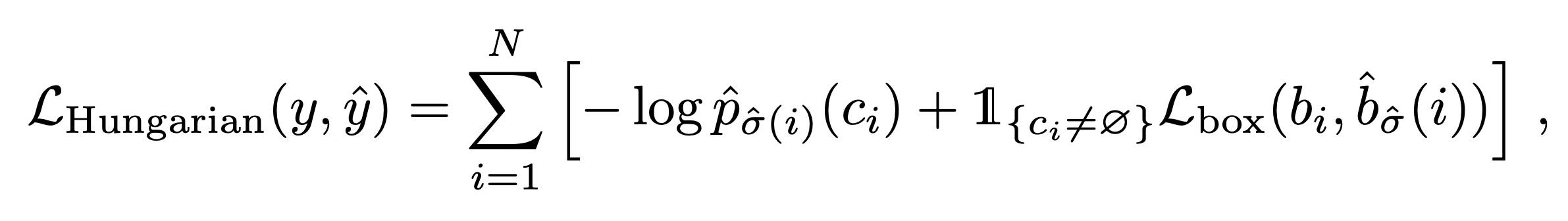
architecture
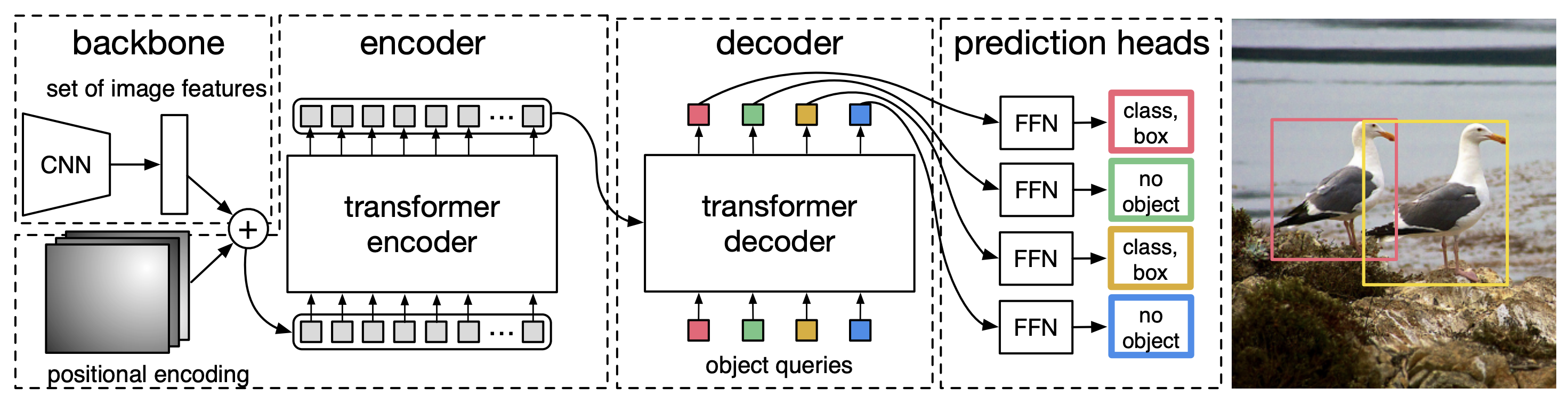
- 기본적인 DETR의 구조는 아래 그림과 같다.
- 우선 CNN backbone을 이용해서 \(H / 32, W / 32\) 크기의 feature map을 추출한다.
- 추출된 feature map은 모든 요소가 Flatten되어 Transformer Encoder에 들어가게 되는데, 2D 위치 정보를 함께 넣어준다.
- Transformer Decoder는 입력 Query로 학습 가능한 N개의 vector를 입력으로 받고, Encoder의 결과물을 Key로 받아 Decoder operation을 수행한다.
- 그렇게 나온 결과물들은 FFN에 넣어 최종적인 결과물인 class 정보와 box 정보를 출력한다.
Auxiliary decoding losses
- 학습이 잘되기 위해서 auxiliary loss를 사용하였다.
- 모든 디코더의 layer output 마다 FFN을 걸치고, prediction loss를 줘서 학습시킨다.
- 모든 layer에 FFN을 들어가기 전에 shared layer-norm을 걸친다.
- Transformer가 10층이 넘어가면 학습이 어렵다는 단점이 있는데, 그것을 해결하기 위한 방법중에 하나이다.
기존 Faster RCNN 계열과의 차이점
- 기존 Faster RCNN은 anchors box들을 이용해 region proposal을 만들고 해당 region proposal들을 토대로 정답 box를 출력했다. 이 과정에서 여러 box들이 결과물로 나오는데 수 많은 box들 중에서 hand craft algorithm을 통해서 가장 근사한 box를 추출해내야한다. 이 과정에서 모든 box들에 대한 iou 계산이 필요로 하기 때문에 많은 시간이 걸린다.
- DETR은 class에 no object를 통해 추가적인 rule based algorithm 없이 object가 있는 것만 box로 출력하면 된다. Faster RCNN도 region proposal을 뽑아낼 때, obejct를 구분하는 모델이 있지만 정답 box와 1대1 매칭으로 학습하지 않기 때문에 수 많은 region proposal이 나와서 추가적인 추출 알고리즘이 필요한 반면에 DETR은 1대1 매칭으로 학습하기 때문에 추가적인 알고리즘 없이 출력할 수 있다.
