Swin Transformer
in Paper
참고
[1] https://github.com/microsoft/Swin-Transformer
[2] https://arxiv.org/pdf/2103.14030.pdf
코드
https://github.com/tinnunculus/SwinTransformer/blob/main/swin.ipynb
- Introduction
- Overal Architecture
- Window based self-attention
- Shifted window based self-attention
- Efficient batch computation for shifted configuration
- Relative position bias
Introduction
- 새로운 window based self attention을 적용한 transformer 모델이다.
- 기존의 window sliding 기법의 self attention는 query token을 중심으로 window를 그려 key, value token들을 설정하여 attention 계산하였다.
- 이 논문의 window based self attention은 이미지를 고정된 window로 나누어서 같은 윈도우 내의 token을 query, key, value로 attention 계산을 하였다. 이것은 기존의 sliding 기법보다 더 효율적인 구현과 메모리 효율성을 결과하였다.
- 다만 고정된 window만을 사용할 경우, 불연속적인 receptive field를 가지는데 이것을 해결하기 위해 window를 일정 크기만큼 선형이동시켜 계산하는 shifted window based self attention 연산도 함께 수행하였다.
- 결과적으로 이 논문의 Transformer 모델은 기존의 비젼분야에서 사용하기 힘들었던 Transformer의 단점을 해결하고, 비젼분야에서 일반적인 아키텍쳐 모델로 사용될 수 있도록 하였다.
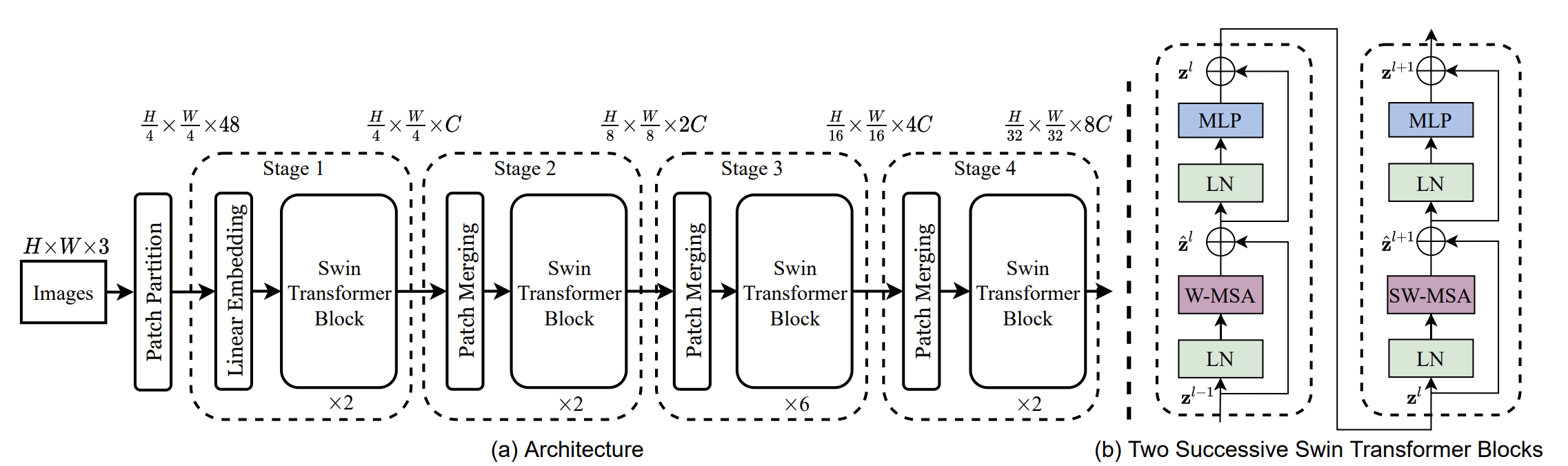
Overal Architecture
- ViT 모델처럼 입력 이미지를 patch 단위로 쪼개서 vectorize한 것을 Transformer의 token으로 사용한다.
- ViT 모델처럼 global self attention을 사용하는 모델과는 달리 window based 논문이기에 작은 크기의 patch를 사용할 수 있다. 논문에서는 4 x 4 크기의 patch를 사용한다.
- 일반적인 Transformer block과는 다른 self attention layer를 사용하기에 swin transformer block이라 이름 붙인다.
- 더 폭 넓은 이미지 scale을 다루기 위해 hierarchical representation 구조를 취한다.
- 인접한 두개의 patch를 concatenation하여 merge함으로써, feature map의 크기를 줄여나간다.
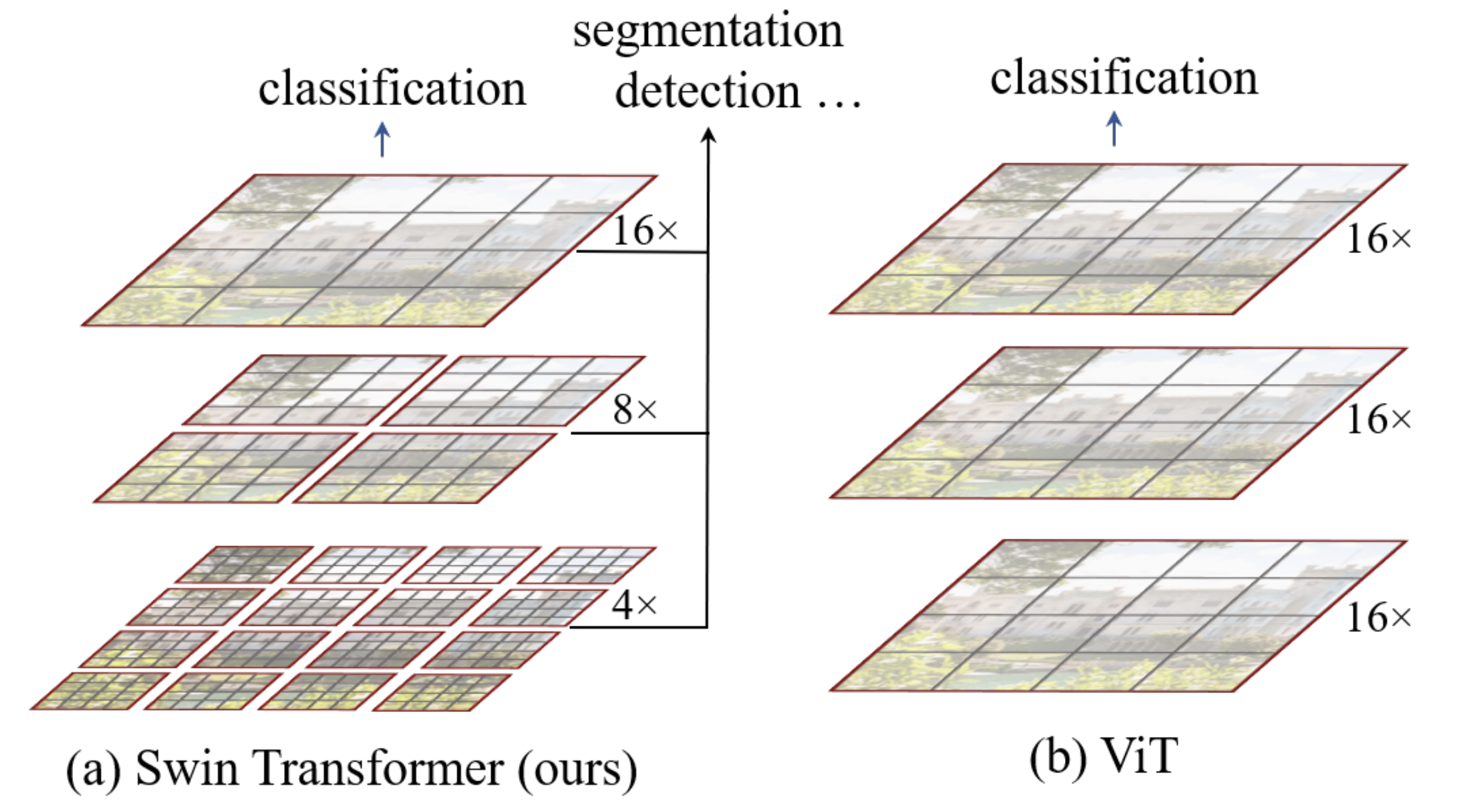
Window based self-attention
- 기본적으로 local window 기반의 self-attention 연산이다.
- window는 feature map을 겹치지 않게 나눠준다.
- 각각의 window에는 M x M개의 patch들이 겹치지 않게 존재한다. 즉 모든 윈도우의 patch들은 겹치지 않는다.
- window 내의 patch들을 query, key, value로 인지하여 self-attention 연산을 수행한다.
- 이것은 이미지 크기의 선형배의 연산량만을 필요로 한다.
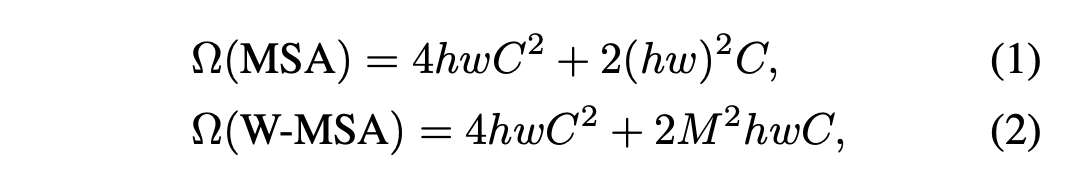
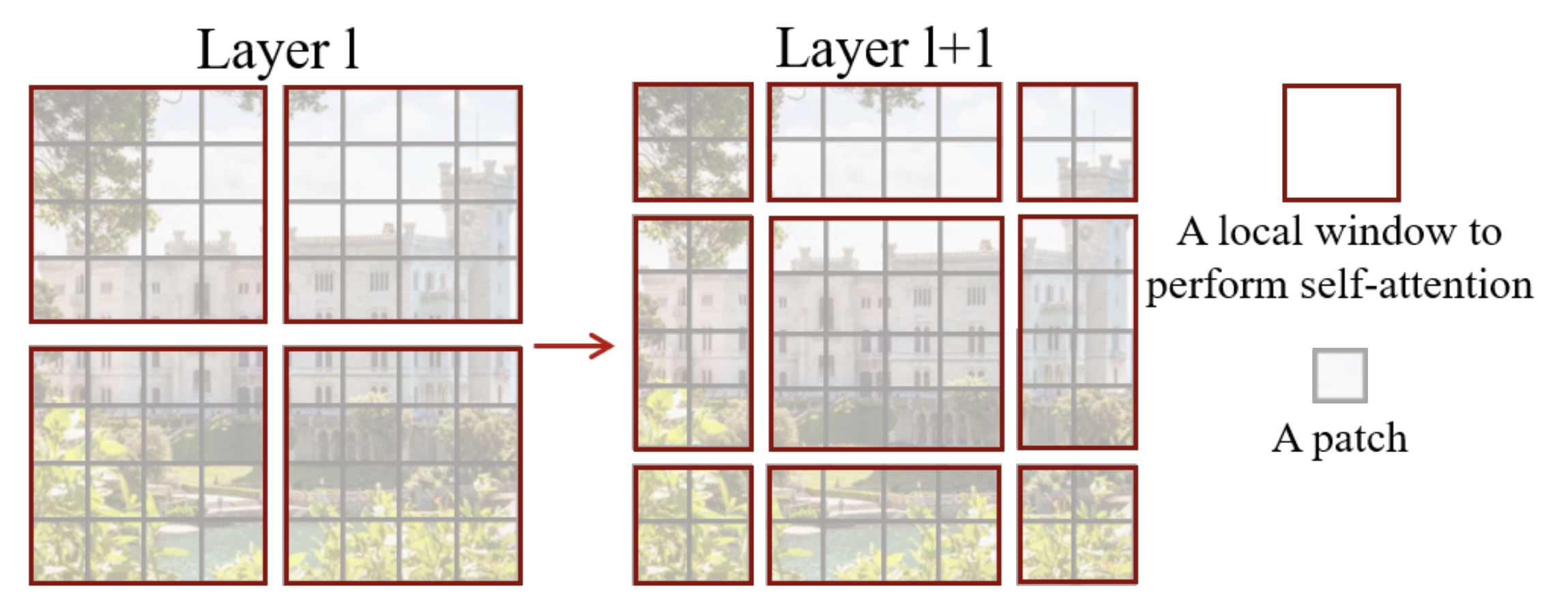
Shifted window based self-attention
- window based self attention 만을 사용하면은 receptive field를 자연스럽게 넓힐 수가 없다. merge를 통해서 넓힌다 하더라도 조각조각 넓어질 것이다.
- 이것을 해결하기 위해 window를 window 크기의 절반 만큼을 선형 이동하여 self attention을 계산함으로써 receptive field를 자연스럽게 넓힐 수 있도록 한다.
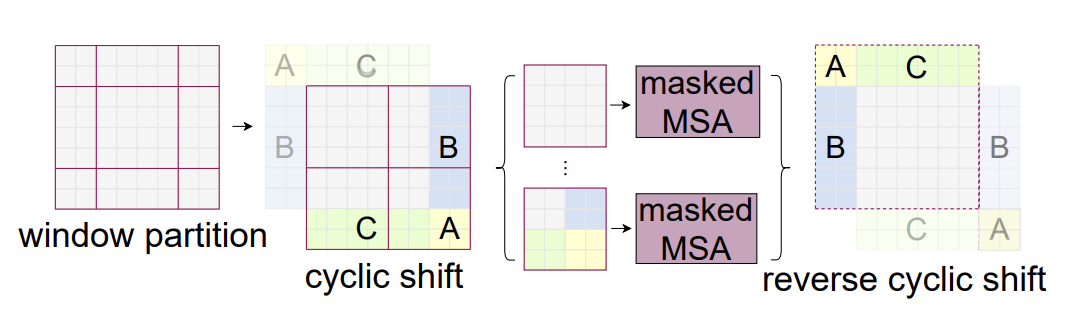
Efficient batch computation for shifted configuration
- window를 shift 하면은 가장자리에 있는 window들은 쪼개져서 나타난다.
- 알고리즘과 구현상의 편리성을 위하여 가장자리에 있는 window를 합쳐줘서 기존의 window의 개수와 동일하게 한다.
- 아예 상반된 위치의 patch들 이므로 attention을 계산할 시에는 섞여서는 안되기에 mask를 씌워서 섞이지 않도록 계산한다.
Relative position bias
- 이 논문 또한 relative position bias를 사용한다.
- 기존의 입력 토큰에 relative position bias를 더하는 것과는 다르게 attention 연산 시에 relative position bias를 더한다.
- 기존의 더하는 bias의 dimension만큼의 단순 학습 가능한 parameter를 더하는 것(여기서는 absolute position bias라 표현하였다)과는 다르게, relative position이라는 개념을 살린다.
- 윈도우 크기가 M일 경우 가질 수 있는 relative position은 \((2M -1)^2\) 이다. 예를 들면 \(M = 3\) 일 경우 (-2 ~ 2, -2 ~ 2)의 경우의 수로 25개의 상대 좌표가 존재한다.
- 가질 수 있는 상대 좌표 마다 학습 가능한 parameter를 두어서 bias를 더한다.
- M = 2 일 경우, B는 아래와 같다.
\(P_4\) \(P_2\) \(P_1\) \(P_0\) \(P_5\) \(P_4\) \(P_3\) \(P_1\) \(P_7\) \(P_6\) \(P_4\) \(P_2\) \(P_8\) \(P_7\) \(P_5\) \(P_4\)

