MaskFormer
in Paper
참고
[1] https://arxiv.org/abs/2107.06278
[2] https://github.com/facebookresearch/MaskFormer
코드
https://github.com/tinnunculus/MaskFormer/blob/master/maskformer.ipynb
Introduction
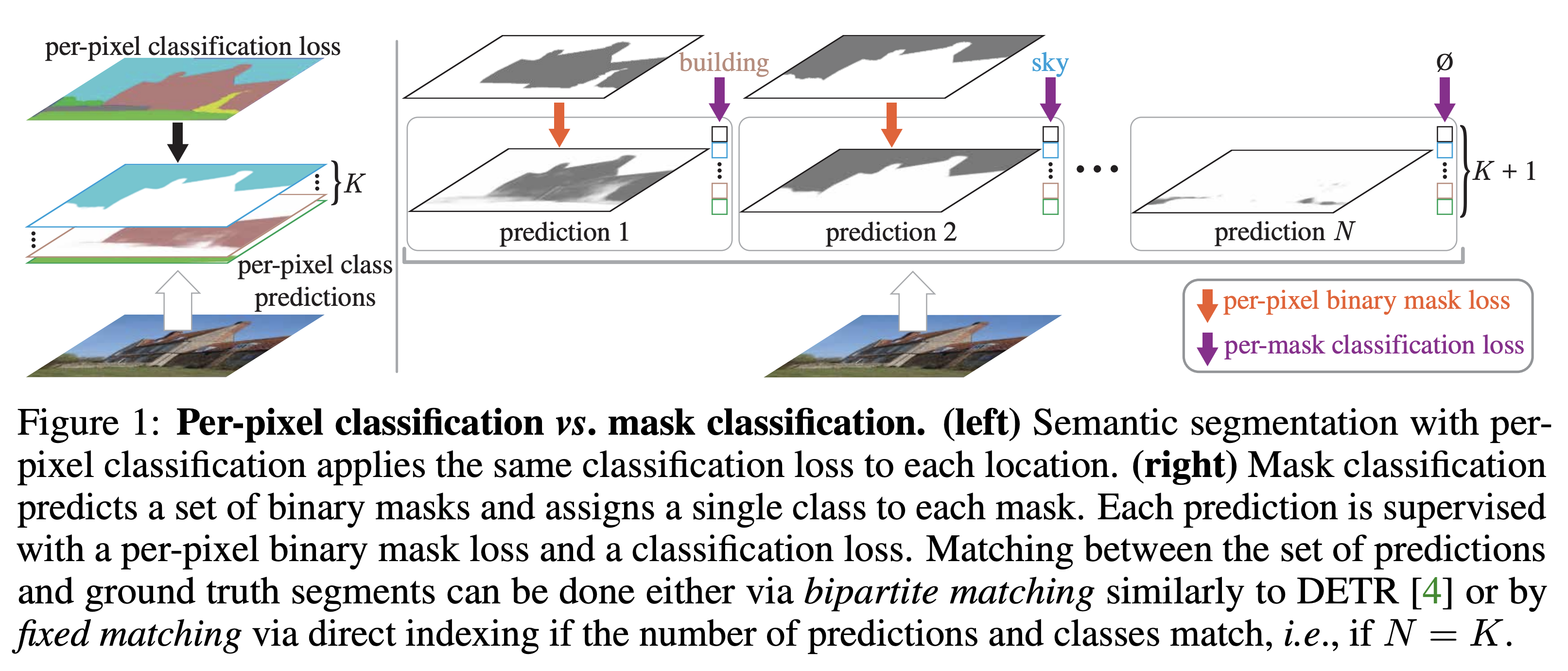
- MaskFormer는 Object dectection 모델인 DETR을 segmentation task에 맞게 수정한 모델이라고 볼 수 있다.
- 그렇기 때문에 핵심 개념인 모델의 구조와 학습 방법으로는 DETR 모델과 거진 유사하다.
- 기존에는 semantic, instance, panoptic 등의 여러가지 segmentation 문제마다 다르게 접근하여 문제를 풀었지만, 이 논문에서는 하나의 학습된 MaskFormer 모델로 inference 방법만 task 마다 다르게 하여 앞에 언급한 segmentation 문제를 모두 풀 수 있다.
Mask classification formulation
- DETR 모델에서는 object detection 모델이기에 트랜스포머의 Query 토큰들이 가리키는 것은 object box 정보였다면 MaskFormer에서는 segmentation 정보의 embedding vector를 가리킨다.
- 이 embedding vector는 후에 per-pixel embedding tensor와 곱셈 연산을 통해 mask segmentation 정보를 가리키고 linear mapping을 통해 mask의 class 정보를 기리키게 된다.
- 나머지 개념은 DETR과 동일하다. class는 no object를 포함하고 있고, bipartite maching을 통해 prediction 정보와 ground truth 정보를 1대1 mapping 하고 학습을 진행한다.
- hungarian matching의 score 함수로 \(-p_i(c^{gt}_j) + L_{mask}(m_i, m^{gt}_j)\) 를 사용하여 bipartite matching 을 진행한다.
- 또한 학습 objective function으로는 아래의 식을 사용하였다.
- 참고로 위의 그림에서 H, W는 원본 이미지의 H, W가 아니다. 0.25배 축소된 크기의 H, W이다.
- mask loss는 DETR과 동일하게 focal loss와 dice loss의 linear combination으로 계산한다.
- 정답 mask는 binary이기에 예측한 mask는 sigmoid를 한번 걸친다. 그렇기에 l1,l2 distance 보다는 cross entropy 계열의 cost가 적합하고, 여기서는 더 구체적으로 focal loss를 사용하였다.
- 또한 iou 계열의 cost인 dice loss도 함께 사용하였다.
- 다른 Transformer 모델들과 같이 필요에 따라 auxiliary loss(transformer decoder의 layer마다 결과를 출력하여 loss를 매김)를 같이 학습할 수도 있다.
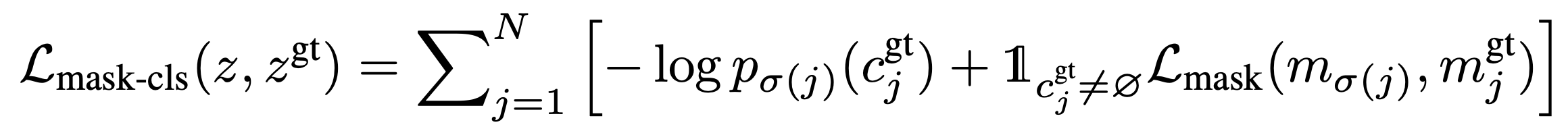
Mask classification inference
- MaskFormer 모델 그 자체로는 단순히 N개의 binary segmentation(sigmoid by pixel) 정보와 class(softmax) 정보만을 가지고 있다.
- 여러 Task에 적합하게 MaskFormer를 inference해야만 한다.
General inference
- 픽셀마다 가장 확률 값이 높은 class를 고르는 것으로 가장 기본적으로 접근할 수 있는 방법이다.
- semantic segmentation을 위해서는 픽셀마다 class 하나 만을 뽑으면 된다.
- instance-level segmentation을 위해서는 같은 클래스의 다른 mask index를 통해 instance들을 구분한다.
- panoptic segmentation을 위해서는 false positive 비율을 줄이기 위해 뭔 짓을 했는데 아직 잘 모르겟다!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
- 각각의 \(mask_i\)에서 가장 확률 값이 높은 class \(c_i\) 를 뽑는다. ( \(c_i = argmax_{c\in\{1,...,K,\varnothing\}}{p_i(c)}\) )
- 이미지의 모든 픽셀 [h, w] 각각에 대해서 가장 predicted probability 값이 높은 class를 고른다. ( \(argmax_{i:c_i\neq\varnothing}p_i(c_i) \cdot m_i[h, w]\) )
Semantic inference
- semantic segmentation을 위한 inference 기법이다.
- general inference에서 처럼 mask마다 하나의 class를 고정하는 것이 아닌 marginalization을 통해 통합적인 값을 구하고 class를 선별한다.
- \(argmax_{c\in\{1,...,K\}}\sum_{i=1}^{N}p_i(c) \cdot m_i[h, w]\) 으로 no object는 취급하지 않는다.
- semantic inference에 대해서는 좋은 결과를 내었지만 낮은 performance 보여주었다.
