Mask2Former
in Paper
참고
[1] https://arxiv.org/abs/2112.01527
[2] https://github.com/facebookresearch/Mask2Former
코드
https://github.com/tinnunculus/Mask2Former/blob/master/mask2former.ipynb
- Introduction
- Contribution
- Mask classification preliminaries
- masked attention
- Multi-scale features
- Optimization improvements
- Improving training efficiency
Introduction
- MaskFormer의 후속 논문이다. MaskFormer와 거의 유사한 모델 구조를 가진다.
- 이 논문 또한 MaskFormer와 마찬가지로 여러 Segmentation task를 하나의 통합된(universal) 모델 구조로 처리할 수 있는 것을 다룬다.
- MaskFormer는 기존의 universal 모델들보다 좋은 성능을 보여주었지만, 여전히 task speicific한 모델들에 비해 단점이 존재했다.
- MaskFormer는 Performance 측면에서 task specific한 모델에 비해 약간 좋거나 나쁜 수준이었지만, 시간 복잡도와 메모리 복잡도 측면에서 매우 비효율적인 모습을 보여주었다.
- 특히 MaskFormer는 이미지 한장(800, 600)을 학습하기 위해서는 32기가의 GPU 메모리를 필요로 한다.
- 또한 MaskFormer는 task specific한 모델에 비해 학습의 시간과 수렴에 어려움이 있다.
- 이러한 퍼포먼스와 학습 및 수렴, 메모리 효율의 문제를 해결하기 위해 Mask2Former 모델을 제안한다.
Contribution
- Mask2Former는 모델의 성능을 개선하기 위해 Transformer decoder에 사용되는 masked attention을 제안하였다. masked attention은 query와 key의 attention score를 계산할 때, 모든 영역에 대하여 계산하는 것이 아닌 이전 layer에서 추출한 mask의 영역에서만 attention을 계산하도록 한다. 구현 상 효율성(시간, 메모리)를 개선하지는 않지만, 더 빠른 수렴과 퍼포먼스의 증가를 보여주었다.
- pixel-decoder의 하나의 feature map을 사용하는 것이 아닌 여러(3개) layer를 사용하여 Transformer decoder의 key, value로 사용하였다. MaskFormer에서는 마지막 layer의 low resolution feature map만을 사용하였다.
- Transformer layer의 self attention layer와 cross attention layer의 순서를 바꿨다. 이것은 모델의 학습을 개선하는 효과를 내었다.
- Transformer 모델에 dropout을 없앴다. dropout은 모델의 성능에 영향을 주지 않고, 오히려 학습의 수렴에 방해하였다.
- 학습 시, mask loss를 계산하는 과정에서 모든 Pixel에 대해서 계산하는 것이 아닌 임의로 추출된 Pixel group에 대해서만 계산하는 방법으로 성능은 유지하면서 메모리 효율성을 높였다.
- MaskFormer와는 달리 Pixel decoder로 FPN이 아닌 Deformable Transformer를 사용하였다.
Mask classification preliminaries
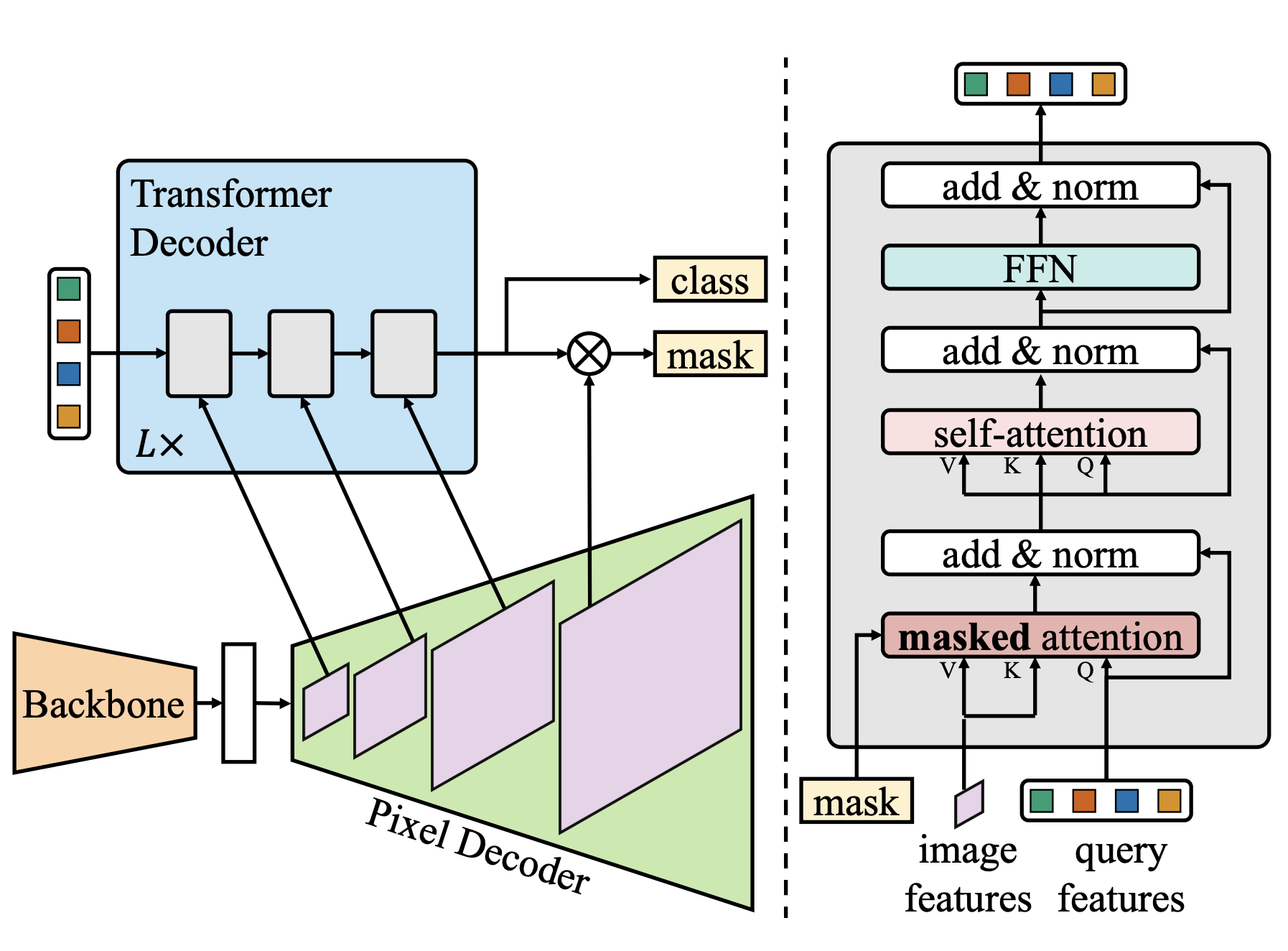
- Mask2Former는 전체적으로 MaskFormer와 동일한 구조를 가지고 있다.
- N개의 bianary mask와 class labels를 추출하는 것을 목표로 한다.
- Backbone 모델을 이용해서 이미지로부터 multi-scale feature map들을 추출한다.
- Pixel decoder를 통해 multi scale feature map으로부터 multi-scale feature map을 추출한다. per-pixel embedding은 나중에 mask embedded vector와 함께 mask segmentation을 만드는데 사용된다.
- Transformer decoder는 고정된 N개의 object queries와 Pixel decoder로부터 multi-scale feature map을 입력으로 받아 N개의 embedded vector를 추출한다. 이것은 선현 변환과 함께 N개의 class labels 결과를 내고, per-pixel embeded matrics와 함께 mask segmentation 결과를 낸다.
masked attention
- 기존의 일반적인 cross attention을 대체하는 새로운 attention 알고리즘이다.
- cross attention과는 달리 모든 영역에 대해서 attention score 값을 계산하지 않는다.
- 이 전의 Transformer decoder layer로 부터 뽑은 결과로 부터 mask를 추출해서 mask가 있는 영역(foreground)만을 attention 계산을 한다.
- 연산량은 동일하다. 하지만 이것은 퍼포먼스를 증가시킨다.
- 다음 Layer이기 때문에 이미 이 전의 Layer의 결과물이 반영된 것이다. 그럼에도 불구하고 mask를 씌우는 것은 일종의 dropout 같은 효과인데 랜덤하게 out 시키는 것이 아닌 흥미 없는 부분을 out 시켜서 더 강하게 attention 하는 것이라고 볼 수 있다.
- 너무 영역을 제한해서 중요한 영역도 버릴 수 있지 않나라고 생각이 들 수도 있지만 뒷 단에 나오는 self attention을 통해서 그 점을 보완해준다.
- 중간 Layer마다 mask를 뽑고 사용하기 때문에 axial training을 같이 해주면 도움이 될 듯하다.
- masked attention layer의 구체적인 연산은 아래와 같다.
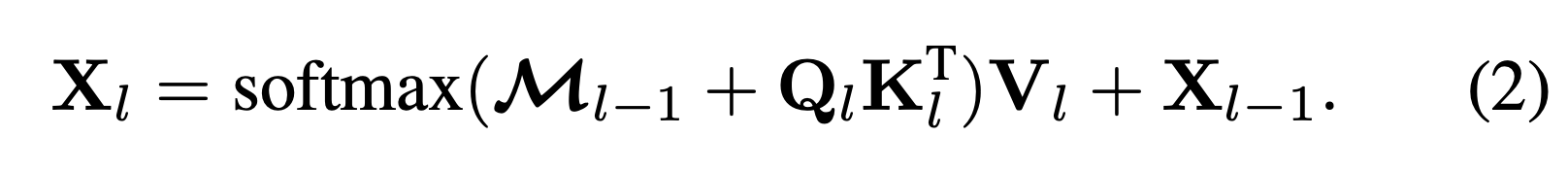
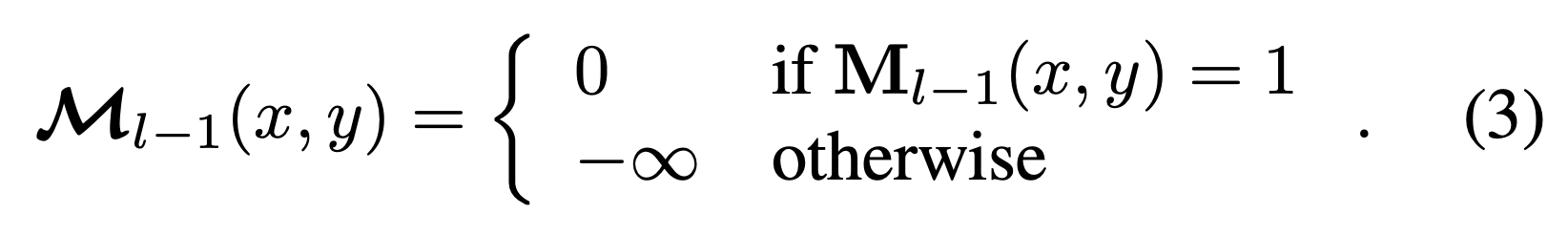
- \(X_l \in R^{N \times C}\) 은 \(l\)번째 layer의 결과물을 나타내고 \(X_0\)는 Transformer decoder에 입력으로 들어가는 queries vector들이다.
- \(K_l, V_l \in R^{H_lW_l \times C}\) 는 Pixel decoder로부터 Transformer decoder에 \(l\) 번째 layer로 들어가는 image feature를 나타낸다.
- \(M_{l-1}\) 은 Trasnformer decoder의 이전 layer로부터 뽑은 결과로부터 mask를 추출(per-pixel embeddings와 함께)한 것이다. per-pixel embeddings의 이미지 사이즈이기 때문에 resize를 거쳐준다.
- \(M_0\) 는 Transformer decoder의 입력으로 들어가는 query vector로 부터 추출한다. 의미가 없어 보일 수 있지만 query vector는 학습 가능한 벡터이기에 학습이 진행되면 진행될 수록 의미있는 mask가 추출될 것이다.
Multi-scale features
- 이전의 MaskFormer와는 다르게 Mask2Former에서는 Pixel decoder의 최종 출력 feature map만이 아닌 중간중간의 layer로 부터 나온 feature map을 활용한다. MaskFormer는 low resolution feature map만을 사용하였다.
- pixel-decoder로 부터 1/32, 1/16, 1/8 크기의 feature map을 추출한다. 1/4는 추출하지 않는데 1/8 feature map을 단순히 upsampling 하여서 per-pixel embeddings를 만든다. 즉 1/4 feature map은 transformer decoder에 들어가지 않고 mask를 뽑는데에만 사용된다.
- 거기에 고정된 sinusoidal positional embedding을 더한다. \(e_{pos} \in R^{H_lW_l \times C}\)
- 거기에 scale-level embedding도 곱한다. \(e_{lvl} \in R^{1 \times C}\)
- 이 세개의 레이어를 Transformer decoder에 L번 반복해서 넣으며, 그 결과로 Transformer decoder의 layer 수는 총 3L개가 존재하게 된다.
Optimization improvements
- 기존의 일반적이 Transformer와는 달리 self attention 과 masked attention의 위치를 바꾸었다. 이것은 논리적으로 더 옳다고 볼 수 있다. 처음 queries vector들은 아무런 의미가 없는 정보이기 때문.
- 모든 layer에서 Dropout을 없앴다.
Improving training efficiency
- 전체적인 학습 방법은 기존의 MaskFormer와 동일하다.
- hungarian maching과 objective function에 쓰인 mask loss를 개선했다.
- 기존의 mask loss는 모든 픽셀에 대해서 distance를 계산하였지만 여기서는 임의의 픽셀을 추출해서 그 픽셀에 대해서만 distance를 계산하였다.
- maching을 위한 mask loss를 계산할 시에는 uniform 하게 모두 동일한 위치의 pixel을 sampling 했으며, 학습을 위한 mask loss 계산을 위해서는 uniform 하지 않고 foreground에 더 중점적으로 sampling을 했으며 mask마다 다른 pixel group을 sampling 하였다.
- sampling시에 사용한 함수로는 grid_sample 함수를 사용하였다. 중복의 픽셀을 선택할 수도 있지만 이 논문에서는 이미지 크기의 비율을 줄이는 것이 아닌 고정된 픽셀 수를 샘플리 하였기에 샘플링 수 보다 이미지 크기가 작을 수도 있다. 그렇기에 매 샘플링 마다 독립시행으로 샘플링을 진행하였다.
- 1/3 수준으로 메모리가 절약했지만 퍼포먼스에는 영향을 미치지 않았다.
