DINO
in Paper
참고
[1] https://arxiv.org/pdf/2104.14294.pdf
Introduction
- 최근 Vision Transformer는 Vision Task에서 Convolution을 대체할 만큼 좋은 성능을 보여주고 있다.
- 이 논문에서는 Vision Task에서 Transformer의 성공이 Transformer의 pretrain 과정에서의 supervison을 통해 설명될 수 있을까 의문을 던졌고, 이것은 NLP 분야에서의 Transformer의 성공 중 하나인 self-supervised pretrain의 사용으로부터 동기를 얻었다.
- NLP 분야에서의 self-supervised pretrain은 language modeling 혹은 문장 중에 비어있는 word를 생성하는 방식으로 학습이 진행되고 이것은 문장의 label을 예측하는 학습보다 풍부한 문장의 인지 능력을 가지게 된다.
- 이미지 분야에서도 마찬가지로 Vit처럼 supervised 학습은 이미지에 포함된 풍분한 visual information을 가지지 못하기에 이 논문에서는 self-supervised 학습을 통해 풍부한 visual information을 가지는 것을 목표로 한다.
- 이 논문에서는 ViT 모델을 이용해서 self-supervised pretraining의 효과를 연구한다.
- 연구의 결과 self-supervised ViT는 supervised ViT와는 달리 명백히 scene layout(object boundaries)을 예측할 수 있다. 이것은 학습 완료된 ViT 모델의 last block에서 볼 수 있다.
- 이런 segmentation 적인 특징이 나타나는 것은 여러 self-supervised method들의 사용을 통한 결과라고 예측할 수 있다.
- 그러나 k-NN을 통한 좋은 classification 결과를 보여주는 것은 momentum encoder과 multi-crop augmentation 기술 덕분이라고 할 수 있다.
- 이 논문에서는 student model과 teacher model을 통해 self-supervised 학습을 진행하는 knowledge distillation with no labels 기법을 사용하고, momentum encoder를 통해 학습을 진행한다.
- 기존의 다른 논문과는 다르게 오직 teacher 모델의 centering과 sharpening을 통해 학습이 collapse되는 것을 막는다.
- self-supervised의 knowledge distillation 학습은 label이 없이 student와 teacher의 output으로만 학습이 진행되기 때문에 학습 도중에 모든 데이터에 대해서 어느 특정한 값으로 쏠려버리는 현상 같은게 일어날 수 있다. 그러한 현상을 collapse라고 한다. 예를 들면 모든 이미지에 대해서 결과 값이 0.5, 0.5, …, 0.5 혹은 1, 0, …, 0 을 출력하는 경우이다.
SSL with Knowledge Distillation
- 이 논문에서 제안하는 모델 DINO는 distillation knowledge 기법을 기반으로 student, teacher model을 학습한다.
- student model과 teacher model은 동일한 아키텍쳐를 사용한다.
- student model의 학습은 모델의 마지막단의 [CLS] 토큰을 통해 이루어지며, student와 teacher model의 결과물에는 softmax를 취하기 전에 특정 값으로 나눠준다. 이것은 output distribution의 sharpness를 컨트롤할 수 있다. 값이 작아질 수록 분포는 더욱 뾰족해질 것이다.
- 뭔가 student의 output에는 sharpness를 하지 않고 teacher의 output에만 sharpness를 하는게 더 맞지 않나… 라고 생각이 든다. 둘다 shaprness를 하면 어차피 다시 값이 평행하도록 학습이 될 것 같은 느낌인데, 물론 학습 극 초반에 평행하도록 되는 현상은 막을 수 있을 것 같지만…
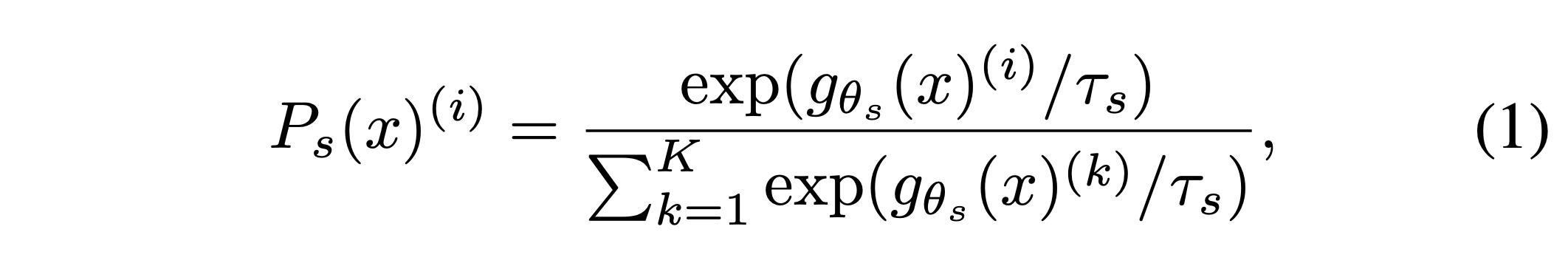
Training student model
- student model과 teacher model이 동일한 이미지를 입력으로 받지 않는다. 만일 동일한 이미지를 입력으로 받는다면 값의 차이가 크지 않아 collapse가 일어날 확률이 쉬워지고, classification에서의 성능이 떨어질 것이다.
- 이미지는 crop되어서 student model과 teacher model에 입력으로 들어가는데, 상대적으로 이미지가 큰 global views \(x_1^g, x_2^g\)와 이미지가 작은 local views group으로 나눠지며, teacher model에는 큰 이미지만이 들어간다. 즉, ‘local-to-global’ 관련성을 찾도록 유도하고, 이것은 classification 문제에 적합하다.
- global view로는 224x224 크기의 image를 사용하고, 기존 이미지의 절반 이상을 덮을 수 있어야 한다. local view로는 96x96 크기의 image를 사용하고 기존 이미지의 절반 이하의 영역을 가리켜야 한다.
- 학습은 stochastic gradient descent를 통해 이뤄진다. momentum을 사용하지 않는 것에 주의하자.
- momentum을 사용하지 않는 이유는 sharpening을 강화하기 위함이라고 생각한다. momentum을 가질경우 기존의 결과의 영향으로 centering되는 collapse가 일어날 수 있겠다.
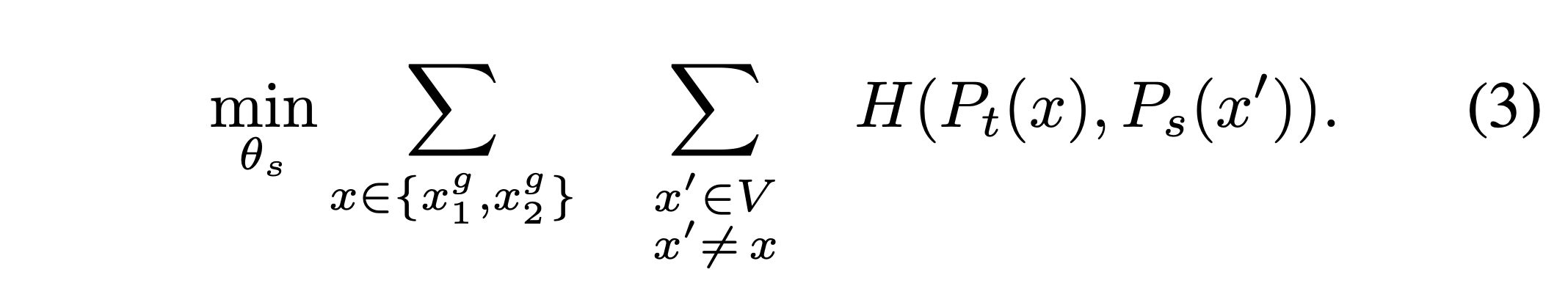
Teacher network
- 다른 knowledge distillation와는 다르게 이 논문에서는 label이 없고 student와 teacher가 동일한 network 구조를 사용하기 때문에 실직적인 teacher는 존재하지 않는다.
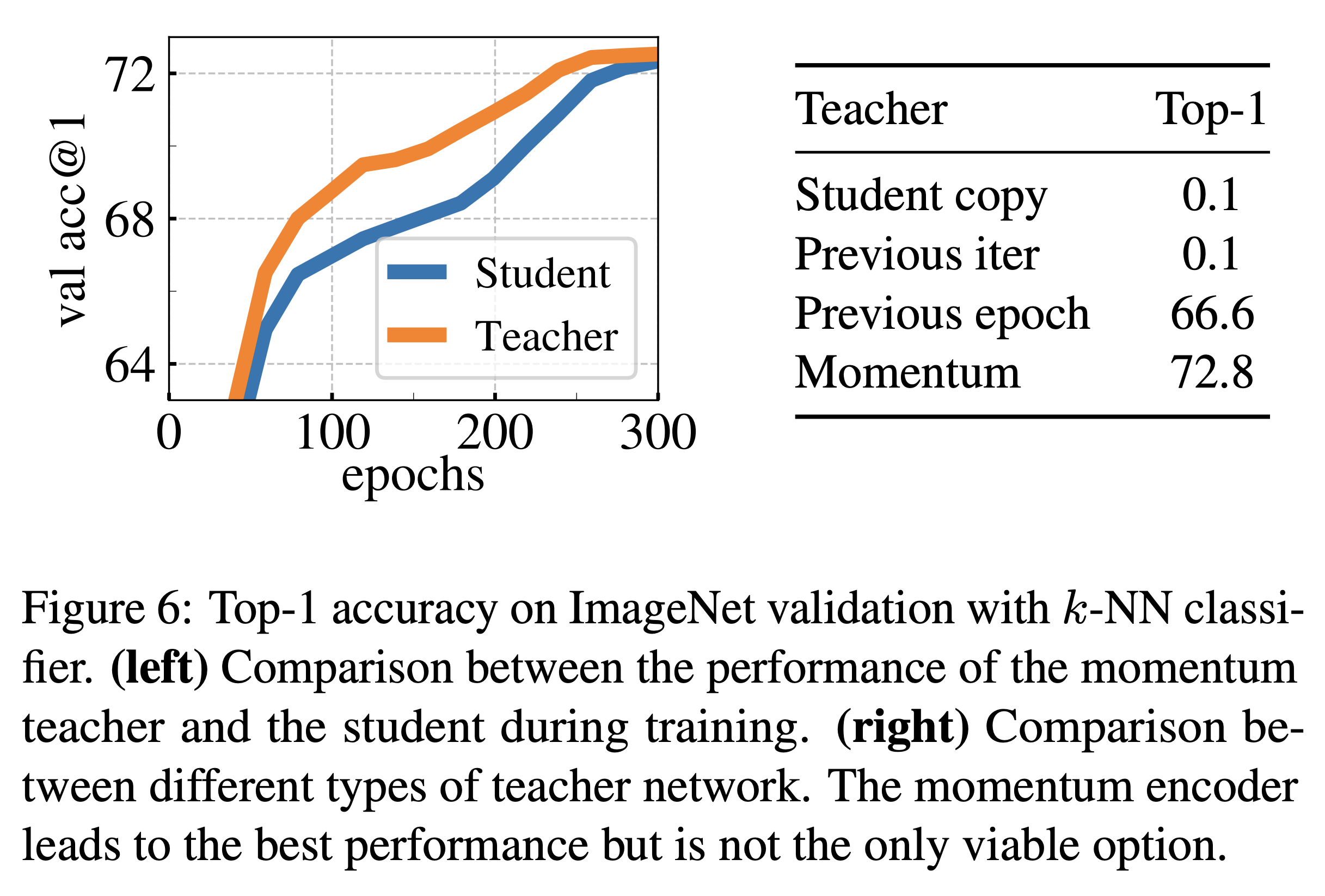
- 하나의 에폭을 학습하는데 teacher network를 freezing시키는 것이 더 좋은 결과를 보여주었고, 단순히 student weight를 teacher weight로 복사하는 것은 모델이 수렴하는데에 실패하였다.
- student weight를 단순히 복사하는 것이 아닌 exponential moving average을 사용하여 momentum을 가져가는 것이 더 학습의 안정화를 이끌어낼 수 있었다.
- \(\theta_t = \lambda\theta_t + (1 - \lambda)\theta_s\) 의 object function으로 teacher weight가 갱신되며, \(\lambda\)는 cosine schedule로 0.996부터 1까지 증가한다. 굉장히 작은 크기의 student weight가 영향을 미친다.
Avoiding collapse
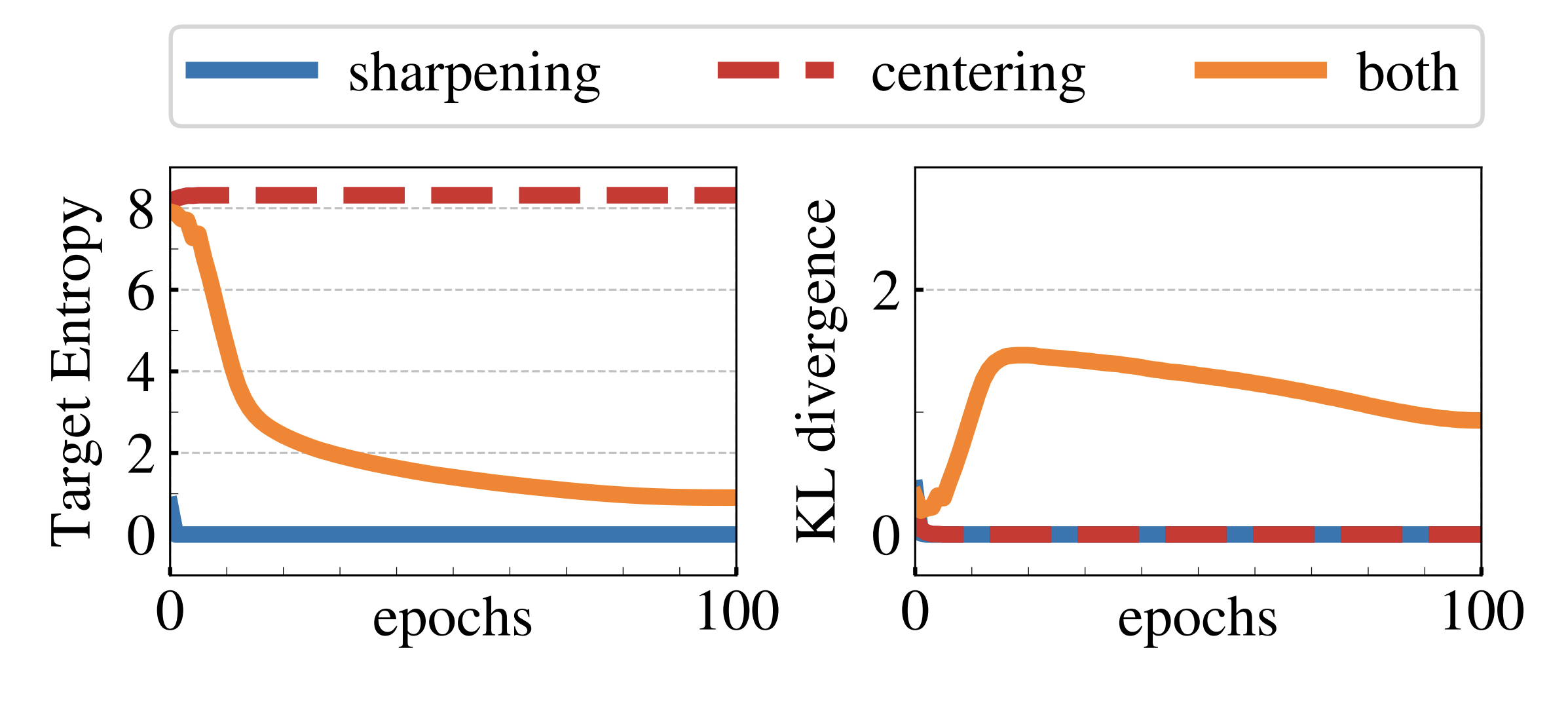
- 이 논문에서는 self-supervised 학습의 collapse를 피하기 위해 Sharpening, Centering 두가지 기법을 사용한다.
- Sharpening은 앞서 보았던 모델의 output에 softmax를 취하기 전 작은 값으로 나눠 분포를 더욱 다이나믹하게 하는 것이다.
- centering은 teacher 모델의 output에 softmax를 취하기 전 기존 output의 momentum을 더해 특정 차원에 dominate해지는 것을 막는다.
- 위 두 기법은 trade-off로 작용되어 학습의 collapse를 막도록 한다.
- 위 그림에서 KL-divergence는 \(H(P_t, P_s) = h(P_t) + D_{KL}(P_t\|P_s)\) 로 계산한다.
Algorithm

