Backward
in Pytorch
참고
[1] https://pytorch.org/tutorials/beginner/blitz/autograd_tutorial.html#sphx-glr-beginner-blitz-autograd-tutorial-py
[2] https://pytorch.org/tutorials/intermediate/custom_function_double_backward_tutorial.html
[3] https://pytorch.org/docs/stable/notes/extending.html#extending-autograd
[4] https://pytorch.org/tutorials/advanced/cpp_extension.html
- torch.tensor.backward() or torch.autograd.backward(tensor, …)
- torch.autograd.grad(outputs, inputs, …)
- Computational Graph
torch.tensor.backward() or torch.autograd.backward(tensor, …)
- 텐서를 기준으로 하여 만들어진 그래프를 따라 텐서들의 gradient를 계산한다.
- gradient는 그래프에 있는 operation의 backward 메소드를 연쇄적으로 실행시킴으로써 수행된다.
- 결과물은 텐서의 .grad 변수에 더해짐으로써 존재하므로, backward를 실행하기전 .grad 값을 0으로 초기화해야 올바른 결과값을 얻을 수 있다.
- backward 메소드를 통해 .grad 변수에 축적되는 gradient는 그래프의 leaf node에서만 행해진다.
- backward를 진행할 때, 기준이 되는 텐서는 스칼라여야만 한다. 그래야 jacobian matrix가 tensor와 shape이 동일해진다. gradient 파라미터롤 고차원의 텐서를 기준으로 할 수도 있는데 이것은 아마 하나씩 여러번 실행하는게 아닐까 추측한다.
- gradient(Tensor or None) : 기준이 되는 텐서의 gradient 값이다. default는 1이다. 기준이 되는 텐서가 스칼라가 아닌 경우에 유용하게 사용할 수 있다.
external_grad = torch.tensor([1., 1.]) Q.backward(gradient=external_grad) # Q.shape = 2- create_graph(bool) : True라면, 미분을 위한 그래프가 생성되며 이것은 다중 미분을 위해 사용될 수 있다. default: False
- retain_graph(bool) : True라면, backward를 계산한 후 그래프가 유지된다. 중복해서 backward 함수를 시행할 수 있다. 반대로 False라면 backward 메소드는 한번만 시행될 수 있다.default: False
- inputs(sequence of Tensor) : None이라면 그래프의 leaf node에 대해서만 .grad에 미분 값이 축적되지만, inputs 인자에 들어온 텐서들로만 .grad에 미분 값이 축적되게 할 수 있다.
torch.autograd.grad(outputs, inputs, …)
- outputs 노드를 기준으로 해서 inputs 노드의 미분 값을 계산해준다.
- backward 메소드와 파라미터는 거의 유사하다.
- 결과값은 input에 대한 gradient 값이다.
- 이 메소드 또한 operation으로 취급하기 때문에 gradient 값이지만 output이고 이 값에 대해서 다시 gradient 계산이 가능하다. 그래프도 만들 수 있다.
out = model(x) grad_x, _ = troch.autograd.grad(out, x) grad_x.requires_grad # True
Computational Graph
- backward를 실행시켜주는 근본은 torch.autograd 엔진이다.
- autograd는 forward 과정에서 데이터들을 저장하고, 모든 operation을 저장한다. Function 객체로 이루어진 DAG(Directed Acyclic Graph)를 형성하며 저장한다.
torch.autograd.Function class
- tensor graph의 기본적인 요소이다.
- forward, backward 두개의 static method가 존재한다.
- forward를 수행하기 위해서 forward method를 직접 콜해서는 안되며, apply() 메소드를 통해서 콜해야한다.
- backward는 현재 노드의 미분 값을 출력해야하며, 체인룰에 의해 grad_output은 해당 operation의 결과물의 그레디언트 값이다. \(\partial L / \partial y\)
- ctx를 변수를 통해 그래프의 노드에 데이터를 저장한다.
class Exp(Function): @staticmethod def forward(ctx, i): result = i.exp() ctx.save_for_backward(result) return result @staticmethod def backward(ctx, grad_output): result, = ctx.saved_tensors return grad_output * result # Use it by calling the apply method: output = Exp.apply(input)- DAG에서 모든 leaf들은 input tensor를 의미하고, root는 output tensor를 의미한다.
- 이 그래프를 root부터 leaf까지 추적(tracing) 함으로써 chain rule과 함께 gradient 값을 계산한다.
forward
- forward pass에서는 autograd는 두가지 일을 동시에 한다.
- Function의 forward method를 실행한다.
- grad_fn(Function의 backward method)을 DAG에 저장한다.
backward
- backward 메소드를 call한 텐서를 DAG의 root로 간주한다.
- DAG에서 저장된 grad_fn을 기반으로 해서 gradient를 계산한다.
- tensor의 .grad attribute에 계산한 gradient 값을 축적한다.
- chain rule을 이용해서 leaf tensor까지 전파한다.
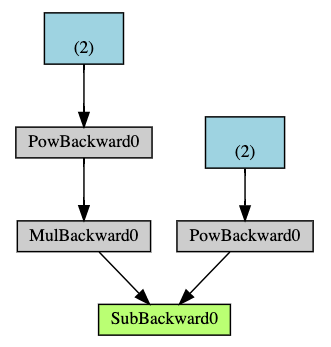
- 아래는 DAG의 한 예시를 보여준다.
- DAG는 forward pass를 중신으로 화살표가 그려진다.
- 파란색 노드는 leaf node를 의미하고, 회색 노드는 backward function을 의미한다.
- tensor의 required_grad 옵션이 False로 되어 있으면 autograd가 DAG로부터 노드를 때어내고 추적하지 않는다.