about requires_grad
in Pytorch
참고
[1] https://pytorch.org/docs/stable/notes/autograd.html
[2] https://medium.com/@mrityu.jha/understanding-the-grad-of-autograd-fc8d266fd6cf
Introduction
- 코딩을 하면서 Tensor 객체가 가지고 있는 requires_grad flag에 대해서 항상 헷갈리는 점이 있었는데, 이번 기회에 정리를 해보자 한다.
- pytorch의 autograd는 forward pass 시에 directed gradient graph를 생성하여, backward() 메소드를 통해 gradient를 계산한다.
- autograd는 forward pass 중에 backward에서 gradient 계산을 위해 텐서들을 gradient function에 저장한다.
- Requires_grad flag가 True인 leaf tensor를 수정하면 오류가 난다. leaf tensor와 intermediate tensor의 차이점에 대해서 알아본다.
- Requires_grad flag가 True인 텐서에 대해서면 gradient를 계산한다. 전령 gradient function이 존재하더라도 requires_grad가 True인 텐서만 골라서 gradient를 계산한다. 마찬가지로 forward할 시에 gradient에 필요한 saved tensor만 저장한다.
- gradient를 계산하는 context로는 grad mode, no grad mode, inference mode가 존재한다. inference mode는 그레디언트를 전혀 계산하지 않는다.
- saved tensor는 값이 바뀌면 안된다. 그렇기에 in place operation의 사용에 있어서는 주의해야한다. 파이토치에서는 leaf node에 대해서 in place operation을 사용하는 것에 오류를 보낸다.
- intermediate tensor에서는 in place operation을 사용한다고 오류를 내보내지 않는다. 자체적으로 clone하여 saved tensor를 저장한다. 이 말은 saved tensor를 저장하지 못한다는 이유로 leaf node에 in-place operation을 못하게 하는 것이 아닌, leaf tensor는 gradient function을 가져서는 안되는 특징을 가지고 있고, clone하여 leaf tensor는 유지하고 새로운 intermediate tensor를 만들어 해결한다면 그건 사실상 out place operation을 의미한다.
Autograd의 처리 과정
- autograd는 reverse automatic diffrentiation system을 의미한다. 말 그대로 forward 연산을 역행하여 자동으로 미분을 계산하는 시스템이다.
- forward pass를 계산할 때, autograd는 gradient를 계산하는 Function을 노드로해서 graph를 만든다. graph에는 노드 Function과 엣지 Tensor와 방향 input, output이 기록되어 있다.
- 이렇게 만들어진 graph는 backward()메소드를 실행 시 forward pass의 역행으로 해서 계산되어 진다. 즉 forward pass에서 입력으로 들어간 leaf node는 backward pass에서 ouput이 되고, forward pass에서 출력으로 나온 output tensor(root)는 backward pass에서 input tensor가 된다.
Saved Tensor
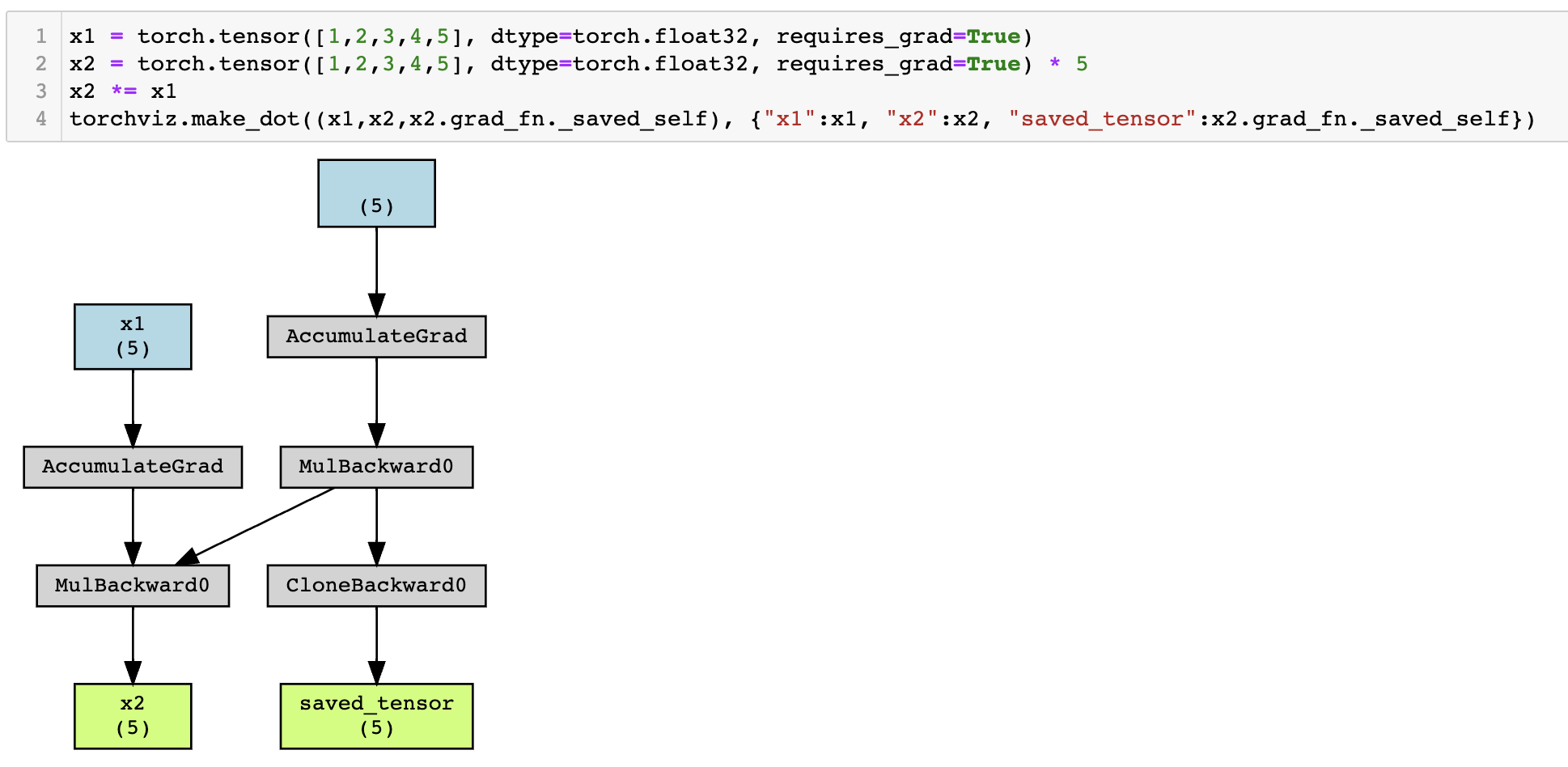
- Gradient를 계산하기 위해서는 forward시에 입력으로 들어갔던 텐서들이 필요할 때가 있다. autograd는 그런 텐서들을 해당 operation에 gradient function과 함께 ctx라는 변수명으로 저장한다. 물론 텐서를 복사 저장이 아닌 참조 저장이다. 그렇기에 한번 저장된 텐서는 별도로 수정해서는 안된다. 오류 발생
- ctx.save_for_backward() 함수를 통해서 텐서를 저장할 수 있으며, ctx.saved_tensors를 통해 불러올 수 있다.
- intermediate tensor에 저장된 gradient function으로 어떤 텐서들이 저장되어 있는지 확인할 수 있다.
x = torch.randn(5, requires_grad=True) y = x.pow(2) # dx/dy를 구하기 위해서는 x의 값이 필요하다. print(x is y.grad_fn._saved_self) # True... 참조형으로 저장되는 모습
Requires_grad flag
- requires_grad는 모든 텐서가 가지고 있는 flag이며, 기본값은 False이다. nn.parameters()로 감싸진 tensor는 기본값이 True이다.
- forward pass 중에 어떤 operation의 input중에 requires_grad가 하나라도 True이면 output Tensor는 모두 gradient function을 가지며 intermediate tensor가 된다. gradient function이 저장되지만 gradient function과 함께 저장되는 텐서들은 모두 저장되는 것은 아니다. requires_grad가 True인 input tensor의 gradient를 계산하기 위한 텐서들만 저장된다. forward pass f(a, b) = a * b이고 requires_grad가 a는 True, b는 False일 때, 함수 f의 grad_fn은 requires_grad가 True인 tensor a의 gradient 계산에 필요한 b만을 저장한다. 반면에 모든 input tensor가 requires_grad가 False라면 output tensor는 모두 gradient function을 가지지 않으며 leaf tensor가 된다.
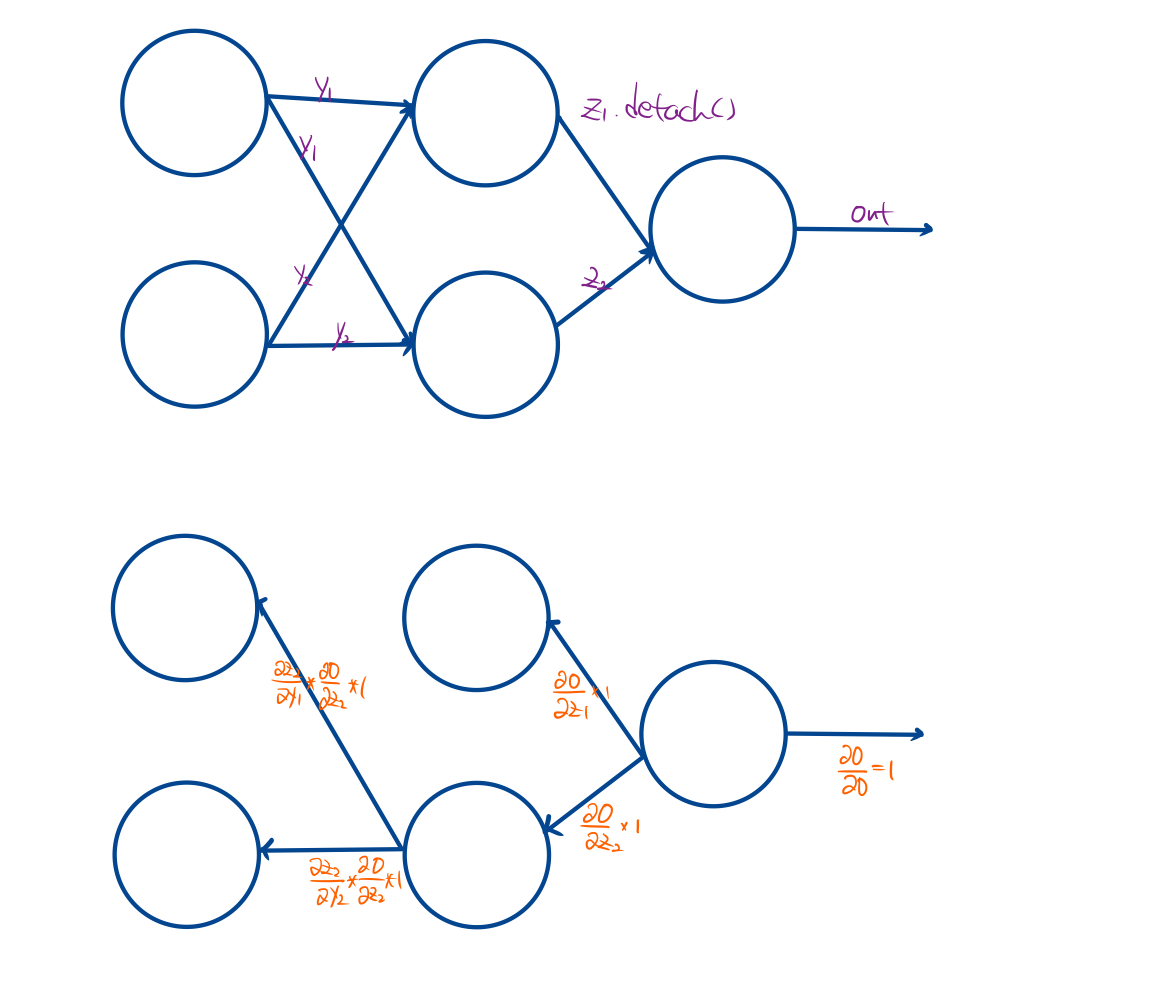
- backward pass 중에는 오로지 requires_grad가 True인 leaf tensor(gradient function을 가지지 않는 tensor)만이 gradient값이 축적된다. intermediate tensor들도 gradient 값을 축적시키고 싶다면 .retain_graph 를 True로 설정해서 grad 값을 축적시키도록 할 수 있다. 하지만 거의 쓰지 않을듯..?
- autograd는 intermediate tensor는 항상 requires_grad가 True라고 가정하고 한다. 만약 intermediate tensor가 requires_grad를 False로 선정한다면 파이토치상에서 오류를 일으킨다.
- intermediate tensor를 gradient 계산이 필요 없어진다면, 즉 backward 그래프를 해당 tensor에서 끊고 싶다면 해당 tensor.detach()를 통해 graph를 끊을 수 있다. 물론 .detach() 메소드는 in-place method가 아닌 graph가 끊어진 새로운 tensor를 복사하는 함수이다. 그렇기에 실제로는 graph가 남아있다.
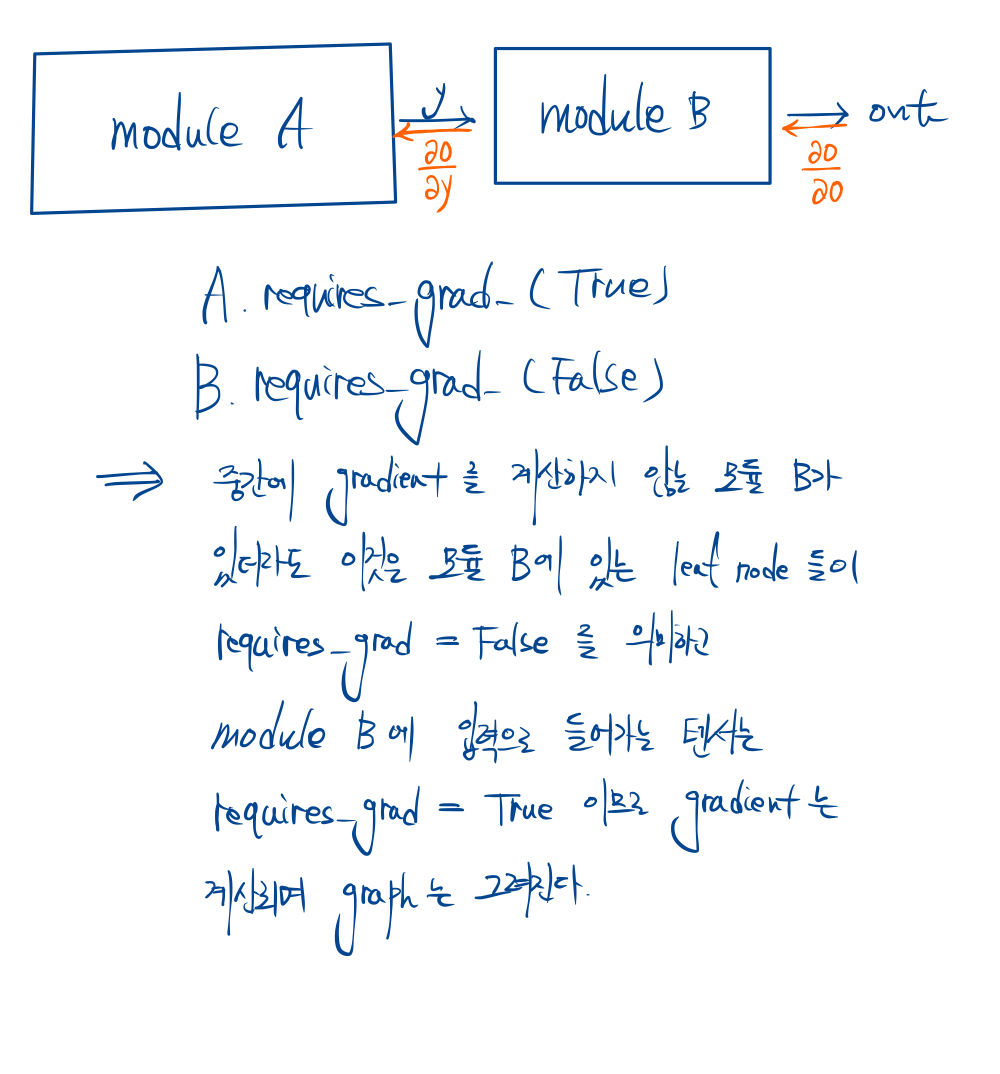
- 어떤 특정 모델을 학습시키지 않고 싶다면 그 모델의 parameter들을 모두 requires_grad = False로 만들면 된다. nn.module.requires_grad_(False) 함수를 사용하자.
Gradient context
- 텐서들의 requires_grad와는 별개로 gradient graph를 다루는 context blcok들이 존재한다.
- 첫번째로 grad mode는 가장 기본적인 mode로써 requires_grad = True인 텐서들에 대한 gradient graph를 계산하는 것으로 default context이다.
- 두번쨰는 no_grad mode로써 context box 내부에 있는 텐서 연산들은 모두 gradient graph를 만들지 않으며 그 뜻은 gradient function, 새로운 intermediate tensor를 만들지 않고 leaf tensor만을 만드는 context이다. 텐서들을 모두 requires_grad=False로 가정하고 계산한 뒤에 동일한 텐서에 대해서 requires_grad를 True로 바꾼다. 즉 값만 바꾼다고 생각하면 된다. 주의할 점은 동일한 텐서라는 점이다. 이름만 같은 다른 텐서는 requires_grad를 True로 바꾸지 않는다.

- 마지막으로는 inference mode가 있다. 이것은 no_grad mode는 해당 context에서만 gradient flow를 생성하지 않고 context에서 출력한 output은 새로 grad mode에서 gradient graph를 만들 수 있다. 하지만 inference mode에서는 이것조차 불가하여 해당 context에서 계산을 한 Tensor는 grad mode로 옮기더라도 더이상 gradient graph를 만들 수 없다.

- 별개로 module의 evalution mode는 requires_grad와는 별개의 기술이다. model.eval()으로 한다고 해서 requires_grad를 False로 계산하지 않는다. nn.Batchnorm과 nn.dropout 같은 Train과 Evalution에 다르게 적용되어야 하는 operation을 위함이다.
in-place operation
- in-place operation이란 연산할 시에 새로운 객체를 만드는 것이 아닌 연산과 동시에 값을 대입하는 operation을 말한다. 예륻 들면 x += 5 같은 더하기 연산이 있다.
- autograd 시스템에서도 in-place operation은 허락되어진다. 하지만 많은 경우에서 안정성이 좋지 않으며 out place operation을 사용하는 것을 추천한다.
- requires_grad = True인 leaf tensor의 경우 in-place operation을 사용하는 것에 주의해야한다. Pytorch에서는 requires_grad가 True인 텐서가 어떤 연산을 수행할 경우 자동으로 gradient graph를 만들며 연산의 결과로 grad_fn과 함께 intermediate tensor를 출력한다. 하지만 leaf tensor의 경우 grad_fn이 없는 텐서를 의미하고 파이토치는 in-place operation을 통해 leaf tensor를 intermediate tensor로 변경하는 것을 허용하지 않는다. 그러나 no grad mode 상에서는 requires_grad를 False로 만들고 계산을 하고, grad_fn을 만들지 않기 때문에 in-place operation이 허용된다.
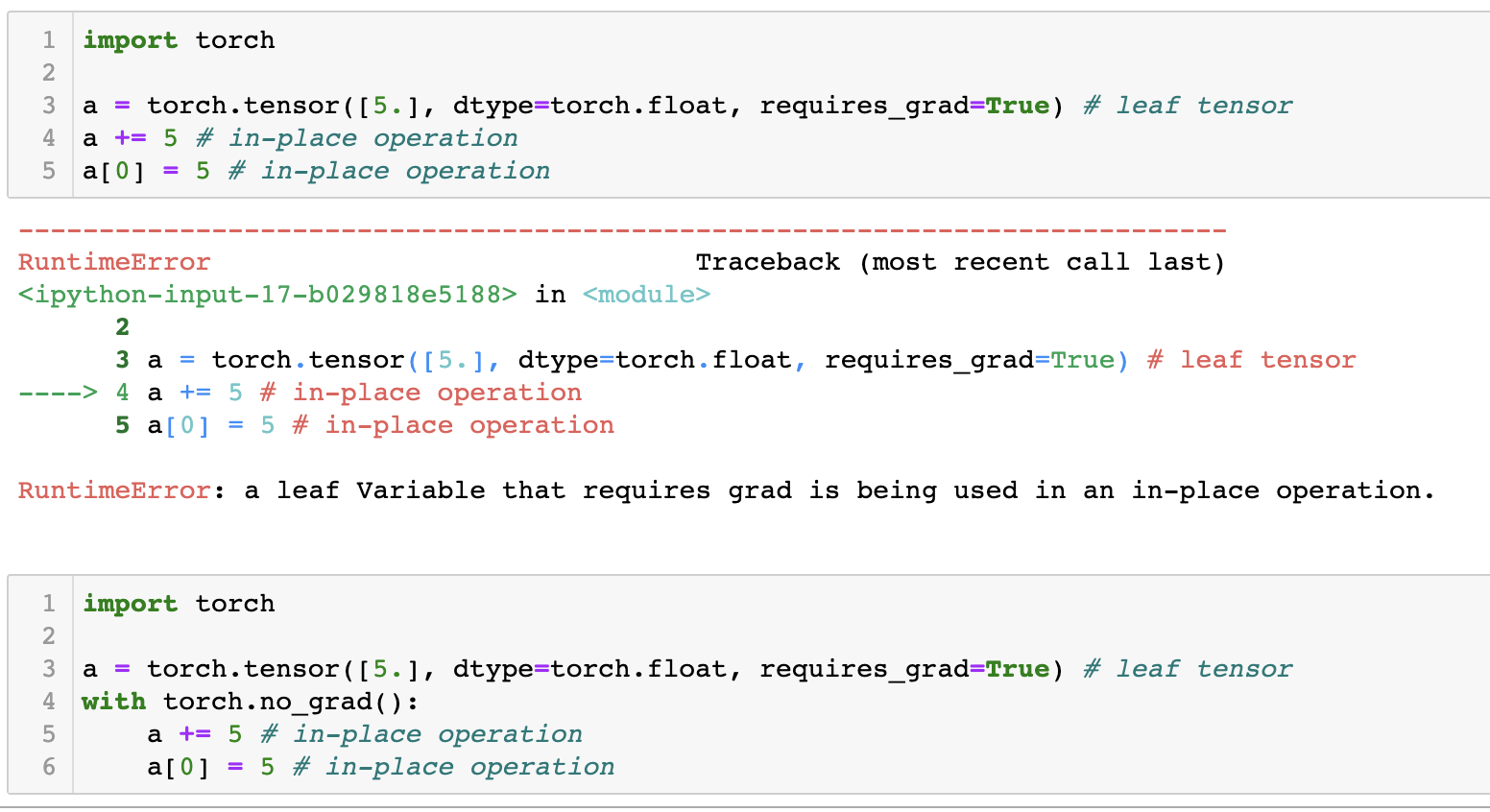
- no grad mode와 함께 in-place operation을 사용하는 경우로 모델의 Parameter를 초기화할 경우가 있다. 이 경우에서는 in-place operation만을 사용해야 실수를 안하기 쉽다. 예를 들면 모델을 생성하고 optimizer에 모델의 파라미터를 등록한 후, 모델의 파라미터를 out place operation을 통해 초기화한다면 optimizer가 가지고 있는 모델의 파라미터와 실제 모델이 가지고 있는 파라미터가 다른 텐서라서 학습이 진행되지 않는다. 그렇기에 파라미터 초기화에는 in-place operation이 사용된다.
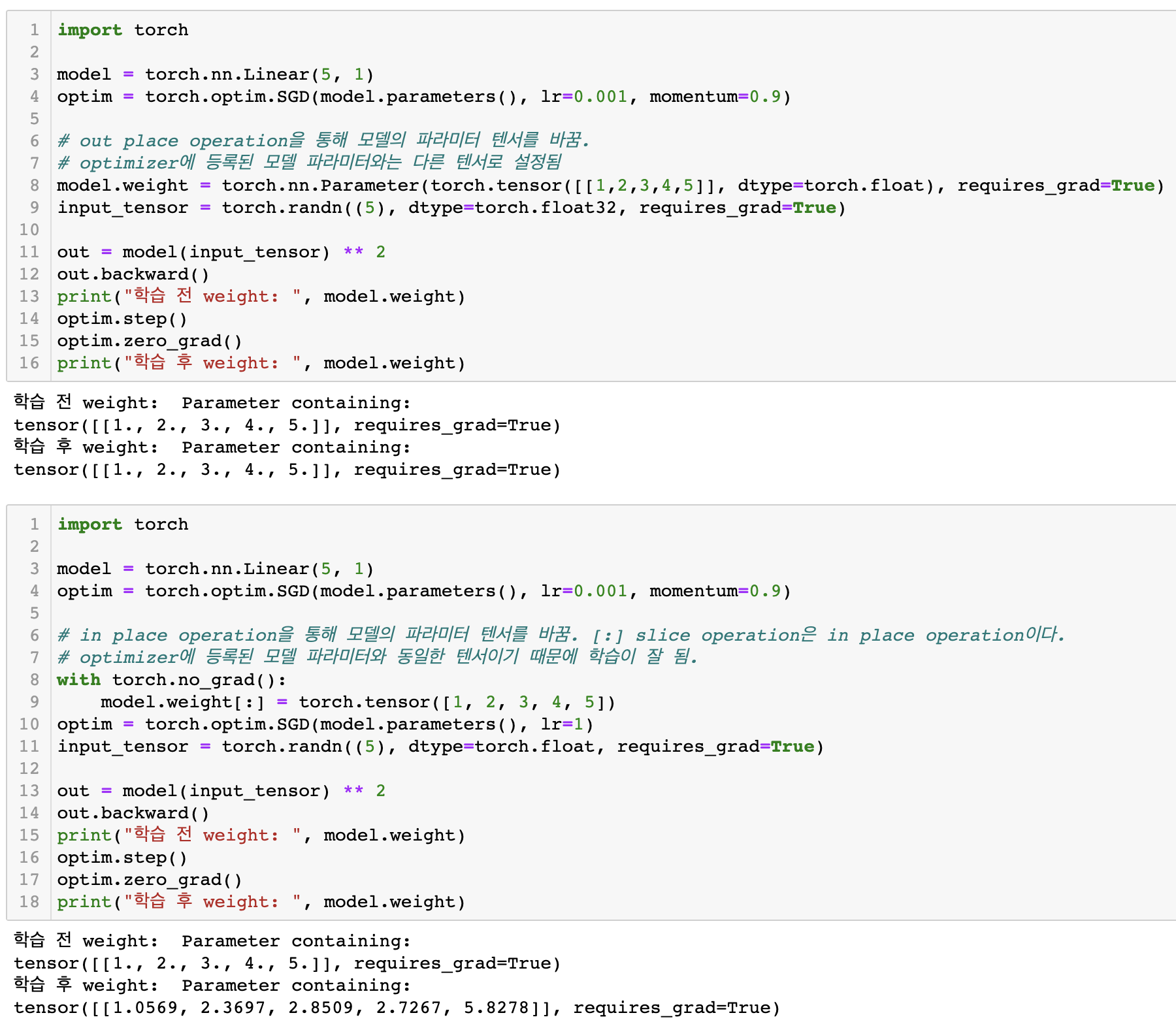
- intermediate tensor의 in-place operation은 파이토치에서 오류를 내보내지 않는다. 그렇다고 파이토치에서 in-place operation을 사용하는 것을 권하지는 않는다. 그럼 어떻게 intermediate tensor에서는 in-place operation이 가능한걸까??
- 기본적으로 requires_grad가 True인 tensor는 operation실행 시 gradient graph을 그리게 되고 gradient function와 함께 saved tensor를 저장한다. 하지만 in-place operation은 자기 자신의 tensor의 값을 바꿔버린다. 그러면 saved tensor와 operation 결과의 tensor는 동일한 객체지만 값이 달라져야하는 현상이 생긴다. pytorch에서는 이 문제를 자체적으로 해결해 주는데 input tensor를 clone하여 saved tensor로 저장하고 input tensor는 그대로 operation을 계산하여 출력된다.
tip
- 모델의 파라미터는 tensor 객체가 아닌 nn.Parameters() 객체를 가리켜야한다. nn.Parameters()는 tensor를 wrap한 것으로 tensor와 동일한데 후에 model.parameters()를 통해 해당 모델의 nn.Parameters()객체를 제너레이터형태로 끌어모을 수 있다.
- optimizer는 초기화할 때, 모델의 파라미터를 넣기 때문에 모델의 파라미터의 값과 grad를 알 수 있다. 물론 업데이트를 해야하기 때문에 값 복사가 아닌 참조이다.
- optim.zero_grad는 optimizer가 가지고 있는 모델의 파라미터의 grad를 모두 0으로 초기화한다. 그렇기 때문에 반드시 그레디언트를 계산하기 전(backward 앞)이나 모델의 파라미터를 업데이트한 후(optim.step) 불러와야 한다. backward와 optim.step 사이에 넣는다면 grad 값은 0으로 초기화 되기 때문에 모델의 파라미터가 업데이트 되지 않는다.
